Review Gates: Where Humans Belong, Where AI Reviewers Belong
*This is Article 11 of Beyond the Coding Assistant, a multi-part series on AI-assisted software engineering at enterprise scale. The full series is available free of any paywall at https://articles.zimetic.com. Previously: Article 10 — Context as Infrastructure.
"Human in the loop" is one of the most over used slogans of the ai coding assistant era. It really doesn't mean a lot until you answer four questions:
- Which human? A senior engineer? A security reviewer? A product manager? A compliance officer? "A human" is not specific enough to be operational.
- At which decision? Every PR? Every architectural choice? Every gate where money or risk is on the line? Most? Some? Almost none?
- With what information in front of them? A naked diff is not the same as a diff with the spec, the design constraints, the prior postmortem, and the AI agent's findings attached. The information determines the quality of the decision.
- What happens when agents disagree? Override? Escalate? Re-route? Block until consensus? Re-run? How many times before promoting to a human? How long to wait before assigning to a different reviewer?
Every one of those questions has a real impact on the flow of the task. Most organizations don't have them written down. They have a vague sentiment that "of course we'll have humans review the AI's work" and they discover, the first time something goes wrong, that "review" turns out to mean "an engineer scrolled past 400 lines of generated code and clicked approve."
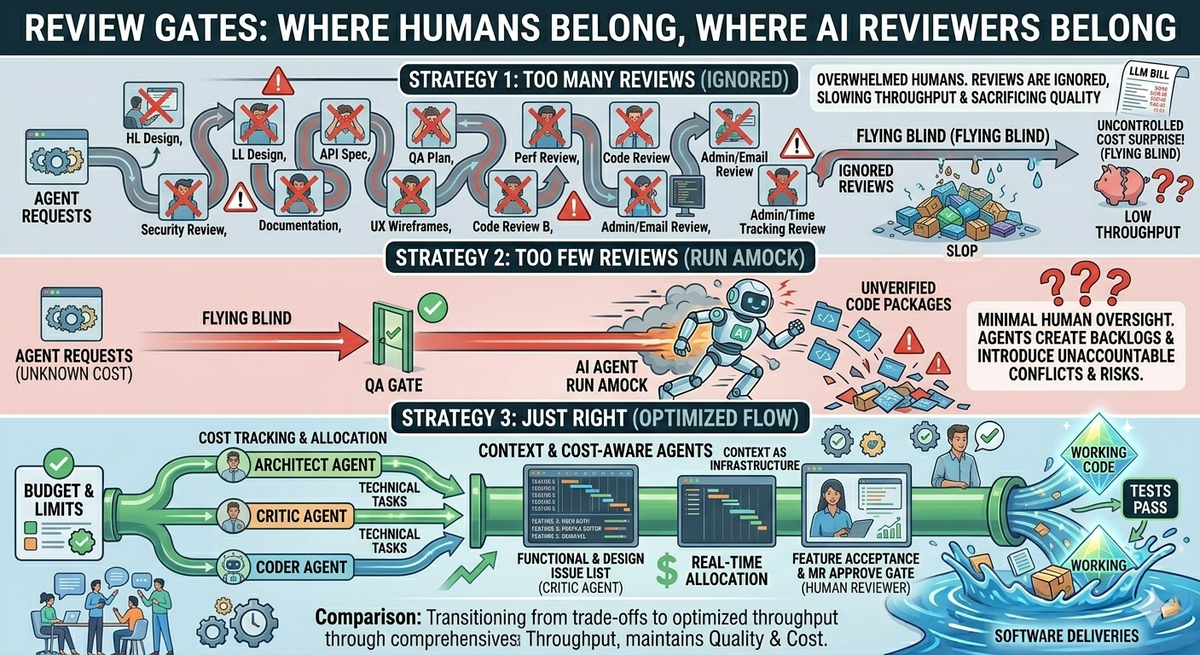
Documenting review gates is how you make it so the orchestrator can consistently and deterministically check to make sure we aren't having agents run amock yet, we also aren't putting undo burden on "humans" to manage more things at once then they are capable of. In this article we are going to discuss review gates as a workflow primitive, why they matter, and where the humans actually belong — which turns out to be far more places than just "the engineer who reviews the diff" and far less often than check this for every task.
The false binary
The default conversation about AI and review tends to land on a binary: fully automated vs. fully human-reviewed. That binary is wrong on the merits. If you make it fully human-reviewed, then the human spends more time reviewing the code than it would take for the human to write the code, if you remove the human completely then the ai runs amok. Neither is the outcome we want, but to build a system that does provide the outcome we want, we need to have more granularity. Who is this human? What are they reviewing? What is the criteria? And sometimes, can the reviewer actually be another agent?
At times the decision isn't cut and dry, if we are making a simple text change of the name of a field in a form, we don't need a human to review the design, we might not even need an actual "design step", we mostly want to make sure the screen displays like we want and that is all the more review we need. So, what is the appropriate gate for this step is often determined by the work that is being done as much as it is the step that is being done. I think we can all agree we have been called in to do a "code review" of a one line change that didn't need a code review at all except it needed someone to check that box.
Real workflows have many decisions. Each has different stakes. Each has different information requirements. Each has a natural reviewer. Some of those reviewers are humans; some are agents; sometimes both. The right question is not "should there be a human in the loop" but "where in the loop, and with what criteria, and with what fallback."
Some decisions belong to humans. A compliance change that goes to a board audit committee belongs to humans. A production deploy at peak traffic belongs to humans. A customer-facing UX call belongs to humans, specifically to the design and product humans whose job it is.
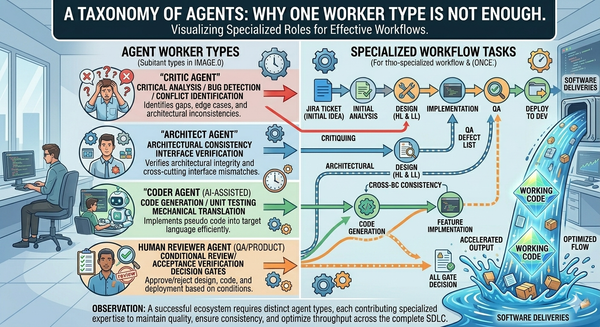
Some decisions belong to AI agents. A documentation rebuild after a function rename belongs to an agent. A conventional refactor against a passing test suite belongs to an agent. A routine API spec update belongs to an agent. We have found great results in having agents review the low level design against the architecture and high level design for things like: missing features, over architected solutions, scope creep, etc. We do this after the design is done, but before the human review on tasks that are of medium or higher complexity level (which is defined in the task definition). This provides the human with the knowledge and confidence that when they review the feature, they don't have to check for all of these things, they can focus on more detailed aspects.
Review gates as first-class workflow primitives
A review gate, in this framing, is a workflow primitive with five properties:
- Type. Human, agent.
- Acceptance criteria. What does "passes the gate" actually mean? Written down before the gate is reached.
- Required approvals. How many? From whom (or which agent)? With what quorum rule (single approval, two-of-three, all-required)?
- Escalation policy. What happens when the gate stalls? When approvers disagree? When the required reviewer is unavailable?
- Audit record. Who decided what, when, on the basis of what information.
A gate is part of the workflow, it's a structural element the work flows through.
Acceptance criteria written before the gate
The acceptance criteria are not "what the reviewer thought was good." They're declared ahead of time, reviewable themselves, and usable by both human and agent reviewers. The criteria should be in the inputs to the task that was just completed, the context of the task, and/or the instructions to the agent.
If you can't write the criteria, the gate doesn't have a clear job, and the review will drift toward whatever the reviewer happens to notice. This is a discipline borrowed from test-driven development and applied to review. Kent Beck's TDD-with-AI argument — leans on the same insight: define what "pass" looks like before you ask anyone, human or agent, to check.
When the criteria are written down, several useful things follow:
- The reviewer's job is bounded. They can finish in finite time.
- An AI reviewer can perform the same check the human would have, against the same criteria, with reproducible results.
- Failures are appealable on factual grounds rather than aesthetic ones.
- The criteria themselves become subject to review and improvement over time.
When the criteria are not written down, "review" devolves to taste, and AI agents — which have to operate on something explicit — fall back to taste-of-the-training-data, which is not your taste.
AI reviewers as a distinct agent category
A code generator and a code reviewer have different jobs. Article 7 made that case as part of the agent taxonomy; this article is where the case lands operationally.
Different jobs. Different context. The reviewer needs the policies, the prior findings, the threat models, the test history. The generator needs the spec, the surrounding code, the conventions.
Different accountability. The reviewer's findings are durable artifacts that downstream agents and humans rely on. The generator's output is one of many candidates that the reviewer evaluates.
Different bias profile. A generator that reviews its own output learns to write code that passes its own self-review, which is not the same as code that's correct. Kent Beck has named this failure mode directly — agents that delete tests to make them pass — and it's structural, not a tuning issue.
Different reviews need different tools. A security reviewer agent for high-risk work probably wants frontier model capability and rich context. Another reviewer may be able to runs on a much smaller model.
A framework that registers "the AI" as one thing and dispatches it to both the generation gate and the review gate is making the same error you'd be making if you asked the same engineer to write the feature and review the feature on the same Friday afternoon. Separate them. Treat them as different agents. The framework needs to make that separation easy, not punish it with friction.
Who are the humans?
Most "human in the loop" framing reflexively means "a senior engineer reviews the diff." That's one kind of human gate, and it's almost never the most important kind. The humans who actually belong in the loop are scattered across the organization (and vary by organization). In my organization:
- Product managers approve scope decisions. The agent proposes a change of scope; the PM says yes, no, or "smaller."
- Designers approve UX decisions. The agent generates a flow; the designer signs off that it matches the product's voice and accessibility requirements.
- QA leads approve test coverage. The agent writes tests; QA validates that the tests actually cover the risk.
- Security reviewers approve security-sensitive findings. The agent flags an injection risk; security decides whether the proposed mitigation is sufficient.
- Compliance officers approve audit-relevant changes. The agent prepares the change; compliance validates that the audit trail is intact.
- Program managers approve release gates. The agent has staged everything; PM checks dependencies across teams.
- Customer success and support approve customer-facing changes.
The "engineer reviews the diff" gate is one item in a long list. The whole-team is what makes that list visible — and the framework's job is to route the right gate to the right human at the right moment, with the right context attached.
This is also where the framework makes good on the promise that AI tooling helps the team and not just the developer. If review gates are first-class and routable, then a PM whose job historically wasn't "review the engineering team's PRs" suddenly has a way to participate in the engineering workflow at exactly the points where their judgment is needed — without being CC'ed on every diff.
Escalation policies
Gates fail. Reviewers go on PTO. Agents disagree with humans. The system has to keep moving.
A few useful primitives:
- Timeouts. A gate that's been waiting 24 hours for the assigned approver is a problem. The policy might delegate, escalate, or route to a backup reviewer. "Wait silently forever" is not a policy.
- Delegation. The assigned reviewer can hand the gate to a peer with the appropriate authority. The system records the delegation.
- Disagreement resolution. When agent and human reviewers disagree on whether the gate passes, what happens? Default to human is one policy. Escalate to a tiebreaker is another. Re-run the agent with explicit context about the disagreement is a third. The framework should support all three; the org picks per gate type.
- Upward escalation. When timeouts and delegation don't produce a decision, the gate escalates to the gate's owner — the team lead, the architect, the security director. Eventually the buck has to stop somewhere; encode where.
Escalation is not an afterthought. It is the mechanism that keeps workflows alive without the team learning to bypass the gates because "the gates are slow."
Patterns from the field
We all have been in situations where gates have been a formality or caused more friction than they have actually been helpful. The goal here is to make it so the gates are flexible enough for us to actually use them for what they are designed for, a review and checkpoint before we proceed. Before I setup this system, I struggled with getting the quality I wanted from the agents. I would find that I was asked to review many times when there wasn't a need for my input and then I would not be asked or wouldn't catch something because I wasn't paying the review the attention it deserved and needed.
This system allows for me to only be involved when a review is important and needs my input. Now, different organizations have different needs here, some are more risk adverse than others. Some industries demand more risk aversion.
Scenarios where human gates are the norm:
- Compliance-relevant changes (HIPAA, SOC 2, PCI-DSS scope).
- Production deploys that affect customers — especially during peak windows or sensitive launches.
- Security-sensitive changes (auth, access control, data export, anything with a CVE history).
- Customer-facing UX decisions, copy, and tone.
- Architectural decisions that constrain future options.
- Migrations, especially data migrations, especially irreversible ones.
Where agent gates are usually sufficient:
- Documentation updates that don't change normative behavior.
- Routine refactors against a passing test suite.
- Internal tooling changes with no external impact.
- Conventional dependency bumps within a tested compatibility band.
- Style and formatting passes.
Closing
Automation is not "replace the human." It is "move the human to the decisions only a human should make, and give them the context, criteria, and tools to make those decisions well."
A well-designed review gate is an organization's judgment, encoded. The criteria are written down. The reviewers are explicit. The escalation policy is real. The audit record is durable. None of that is overhead — it is what turns "we have a review process" from a meeting-culture artifact into a workflow primitive that scales.