Pools and Reservations: Shared Infrastructure for AI Engineering
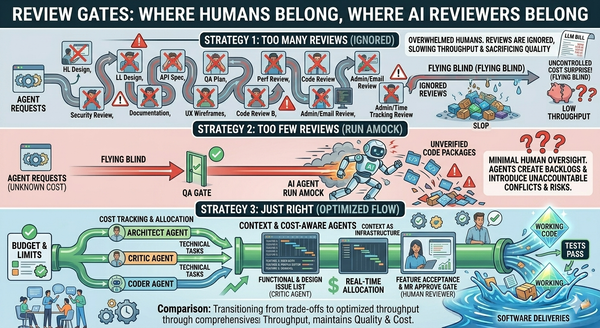
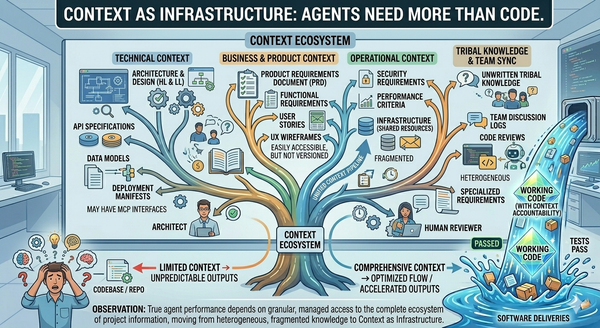
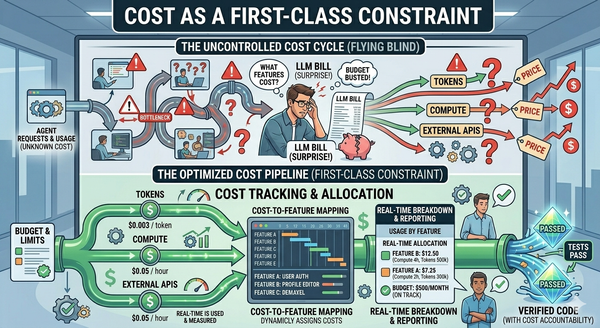
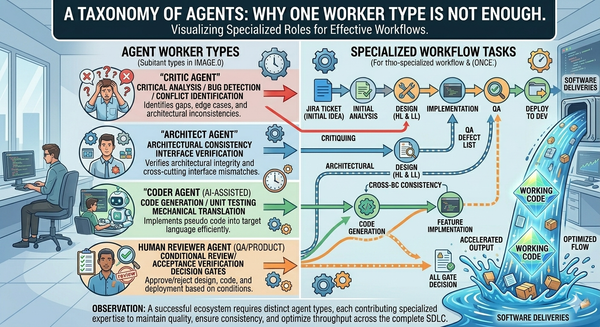
This is Article 8 of Beyond the Coding Assistant, a multi-part series on AI-assisted software engineering at enterprise scale. The full series is available free of any paywall at https://articles.zimetic.com/. Previously: Article 7 — A Taxonomy of Agents. Coming next: Article 9 — Cost as a First-Class Constraint.
In most organizations the engineers oscillate between sharing resources and spinning up some ephemeral instances of resources. Sometimes, they will spin up a local version of an app if they need to test against it, or a local simulated message bus to develop against. Other times they will run against the instance in dev. Often this means changing some configuration settings when they start the app, and/or maybe doing some sort of network routing so that they can reach the instances they need. Sometimes this means coordinating the usage with others.
This worked reasonably well when engineers were working on one thing at a time, and they didn't mind spending the time to configure their system to do that work. But when they are starting up three or more agents to do work all at the same time, those agents are sharing with many more "engineers" than before. And they are all competing for these resources. The need for more ephemeral resources and/or better sharing of resources becomes key to keeping these resources from becoming a bottleneck.
This is why the concept of a 'project' becomes key to making it possible for a large number of agents to work on a large number of tickets at the same time. And why this concept is key to taking the burden of defining what is required and how to configure it in a way that is repeatable and automatable so the engineer is not spending all their time doing the toil work of configuring ephermal configurations for agents to work and tearing them down.
What is a Project then?
Simply put, a project is the definition of the resources that you need to be able to work on tasks that impact this system. Some systems have a large number of other systems they interact with and may have many 'projects' or configurations of resources needed to do work on the various parts, but in general a system in your organizations ecosystem will have a relatively few set of configurations you will need to spin up when you are working on that system.
It starts with the git repos that are needed (both the primary repo for the system and often secondary ones for terraform and other ancillary components of the system). The project then goes on to define runtime components that are needed to run the system: databases, message busses, shared memory systems, etc. The project also includes definition of everything else that an engineer would have to configure to make the system work enough for the development task to be able to be performed. More specifically to be able to test and reproduce the functionality needed to verify the development work being performed. It also includes any systems, tools and frameworks needed to make the changes needed to engineer, implement and test the change being requested. So things like compilers, linters, qa frameworks, performance testing tooling, etc.
This definition is what allows the orchestrator to be able to build an 'engine' where the AI assistants can do their work and know that they are able to reproducably work on the system. If the environment isn't a reproducible one, then how can we expect the agent to know if the change worked or not?
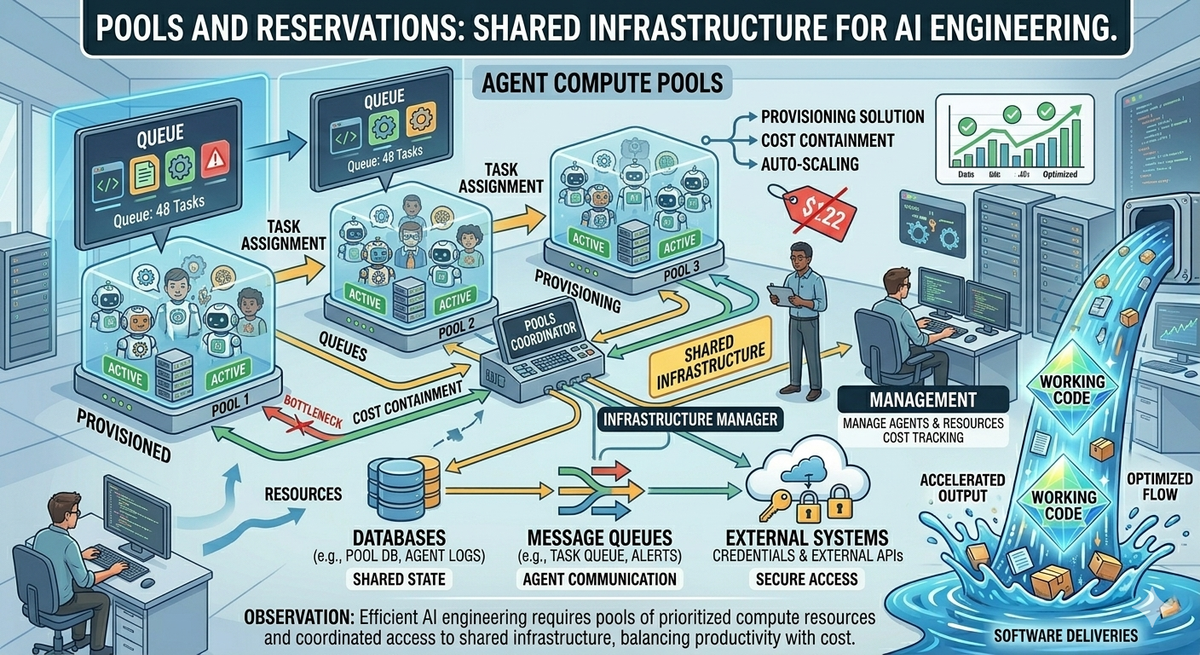
Why pools of engines
Configuring resources is not a cheap process. The cost is high in several ways. On many systems this work is equal or more than the work of actually writing the code, especially when the project is one that is not often worked on, so folks don't remember how it needs to be configured to get it to work.
The cost is also high in that we often have to have tools that are not easy to reproduce on our local machine, large databases, third party apis, etc. These are resources that we can not or do not want to duplicate for each and every task that we are going to work on. Duplicating these resources often costs time, money, and compute resources. While engineers only had to do this a few times a week, and often could just reuse the same configuration for several tasks, with AI agents and the pace we can work at today, this is something that often happens more than once a day, now it becomes a big percentage of the engineers time.
For this reason, it is ideal for us to be able to create a pool of 'engines' that have the resources available that the project needs, or knows how to spin them up quickly and can thus run several tasks in the sdlc for all the stories that require that project. This allows the work to be spun up and down quickly while also saving on the cost and effort that the engineer must do to spin up these resources. It also allows for better cost containment and accounting of the costs for the development work for new features on this particular project. We can better track those costs and assign them to the features so we have a better idea of what our costs are.
How do we share these pools of engines?
If we now have pools of engines where our agents can run, how do we use them? The best approach I have seen is to be able to spin them up and down in a kubernetes or docker type environment so that they are available to all the engineers who are working on that project or set of projects. This also provides a repeatable environment so we can duplicate our results easily and one where we can manage the resources that are available to the agent so it can be given permissions to do the work we need done and no more. If it messes up the environment, we are ok with that as we created the environment to be a test bed for the agent. No production damage, and no damage to the engineer's machine.
So with a pool of engines available in docker containers or kubernetes pods, how do we use them in a shared and fair manner? The mechanism I've found most effective is a job queue for the pool. Now, in most cases, we don't have so many engineers (and agents) scheduling so many things to be done on a specific project that the pool can't keep up with the demand. However, by having a job queue, it means we can schedule and perform work based on a priority system.
What goes into calculating the priority and picking the next task/step to work on? Well there is the priority of the feature/story to begin with, is this a nice to have feature, or is this a hotfix that has to go out now? Then there is what resources does this particular task need and are those resources available? If this is a design task, we don't need the database spun up, but if it is a QA task we might need all the resources. Are those resources available or something we can spin up, or are they something we need to reserve and is one available for that reservation?
There are other considerations that need to be taken into account and as always different orgs will want to take into account different things to determine the best algorithm for themselves, but you get the picture here. And of course, as we all know from experience there will be situations where we will have to redirect the scheduler so the task we really want and need done NOW, is first in the queue.
Reservations as the coordination primitive
A pool with shared resources isn't enough on its own. The agents in the pool need a way to coordinate around those resources without stepping on each other. The pattern is well-established in databases and batch schedulers: agents don't just "use" a shared resource. They request a reservation — exclusive or shared, read or write, scoped appropriately. The reservation manager grants, queues, or refuses. Reservations have lifetimes. They can be renewed, released voluntarily, force-released if the agent hangs, or timed out automatically.
A useful reservation includes:
- What is being reserved (which database, which schema, which topic).
- How it's being used (read, write, exclusive lock).
- Scope of the reservation (whole database, schema, table, row range — granularity matters; more on this below).
- Owner (which agent, which work item).
- Lifetime (a default with renewable extensions; not "until you remember to release it").
- Priority (production-bug reservations preempt feature reservations the same way the priority queue describes).
The agent makes the request. The reservation manager grants or queues. The agent does the work. The agent releases when done. If the agent fails, the manager force-releases after the lifetime expires. Standard distributed-systems hygiene; nothing exotic.
What's new in AI orchestration isn't the mechanism — it's the volume and the role mix. A pool full of specialized agents will be making reservation requests at a rate human teams never approached, and the patterns of contention will be different. Agents tend to ask for the same kinds of things at the same times because their workflows are correlated.
The distributed-systems problems that come along
Once you commit to reservations, a familiar set of problems comes with them. Naming them and pointing at the prior art is most of the work.
- Waiting queues with fairness. Many requests arrive at once. Some have higher priority. The queue policy has to balance priority against starvation prevention.
- Deadlock detection. Agent A holds a reservation on database X and asks for one on database Y. Agent B holds Y and asks for X. Classic deadlock; the wait-for graph cycles. Detection and breaking are well-studied.
- Forced release. Agents hang. They time out. They get killed. The manager has to know how to take their reservations away cleanly. Lock leases with renewal — the same pattern Chubby and ZooKeeper made famous.
- Priority inversion. A low-priority reservation blocks a high-priority one. Solutions range from priority inheritance (the holder temporarily inherits the waiter's priority) to preemption (force-release the lower-priority hold). The right answer is workload-specific.
- Two-phase locking. When a single work item touches multiple resources, lock all you'll need, in a consistent order, before doing the work. Standard ordering rules prevent the deadlock that ad-hoc locking produces.
- Capacity limits and backpressure. Shared resources have limits — connection pools, rate limits, disk I/O, memory. A reservation system that ignores capacity will happily grant reservations the resource can't honor. The fix is capacity-aware reservation plus backpressure.
None of this is new. All of it is well-studied in databases and operating systems. AI orchestration's job is to adopt this body of work, not invent a new one.
The AI-specific twist: agents can be re-planned
The classic batch scheduler can't ask its workload "would you like to do something else for a while?" The job is the job. It runs when the resource is available; otherwise it waits.
AI agents can be re-planned. An agent waiting on a database reservation can instead be asked to do the documentation task that doesn't need the database, or to refine an earlier pass on the same work item, or to explore an alternative design while the database is busy. The orchestrator has choices the batch scheduler didn't have.
This is the strongest distinguishing claim AI orchestration gets to make about its scheduler design. It allows the agent and its engine to still get work done while waiting for a queued resource.
Scope and granularity
Reservations don't have to be all-or-nothing.
- Database-level. "Lock the whole database." Coarse but simple.
- Schema-level. "Lock the public schema; agent B can have the analytics schema."
- Table-level. "Lock the orders table; agent B can have the users table."
- Row-level or range-level. "Lock orders where order_id between X and Y."
Finer granularity unlocks more parallelism and more contention. Coarser granularity is simpler and less efficient. The trade-off is familiar from any database optimization story; the answer is workload-specific. A useful default for AI orchestration: start coarse and if a resource is becoming the bottleneck, then work to reduce that point of contention. As you scale up, you'll discover which resources need attention to keep the system running fast.
What pools plus reservations unlock
Putting it together, this combination of features unlocks the scalability that can't be made available by simply running a bunch of coding agents in separate shells on your local machine:
- Cost visibility per pool, per project, per work item. Cost is attributable to the artifact that consumed it, not the seat that triggered it. We will discuss this in more detail in our next article.
- Fair-share scheduling that reflects organizational priorities. Security teams get the cycles they need without negotiating with the feature team's calendar.
- Elastic scale. Pools grow and shrink. A release weekend can spin up increased capacity and then spin it down when no longer needed.
- Preemption. Urgent work can interrupt non-urgent work cleanly, with checkpoints that let the preempted work resume rather than restart.
- Cross-agent coordination. Agents in the same pool can share context, share memory, share resource reservations.
- Resilience to the failure modes above. Reservation visibility, lease renewal, deadlock detection, and capacity-aware backpressure turn the standard "multi-agent system goes weird in production" stories into ordinary engineering problems with known solutions.
The cloud-transition analog
The industry has lived through this transition twice already. Physical servers gave way to virtual machines, which gave way to shared cloud compute, which gave way to serverless and shared platform services. Each move was driven by the same observations: per-individual is wasteful, coordination is necessary, and the right unit of allocation is the workload, not the user.
AI orchestration is in the early-virtual-machines phase right now. The seat-licensed assistant is the developer-laptop equivalent. The next step is shared pools with proper coordination primitives. Given the cost pressure — token economics that don't subsidize per-seat overhead anymore — the relearning probably happens whether anyone plans for it or not. Catching up on purpose is cheaper.
What this means for the developer experience
When I proposed this approach to our team it caused concern about "rate limiting" or a scarcity of resources. People didn't want to be gated by not having what they needed. So, I approached it another way. We have pools where everything is configured for you, you don't have to configure anything to work your ticket. If you don't like them, or they don't meet your needs, configure away on your local machine.
In a short time, the engineers who tried these pools of resources were hooked, "do we have one for project x?", or "How do I add this resource to project y?" We quickly found what configurations we needed and what we did not need as many resources for. And since we were able to scale to zero, keeping odd configurations around was not wasteful.
This changed the discussion from one of being forced to do something to getting to use something that is easier. That took away the concern and fear of losing control over their work environment and made it easier for folks to migrate to these environments.
Closing
By defining what a project needs, we make it easier for agents to be able to reliably know what they need and schedule those things so they can get their work done without assistance. And it frees up engineers to not have to do the toil work it takes to be able to create these environments which is often frustrating especially when the project is infrequently used.
Coming next
Article 9: Cost as a First-Class Constraint. With pools and reservations in place, the next question is how to run them deliberately. Cost has to be a scheduling input, not a billing line. Budgets have to be a control surface, not a reporting layer. Model routing, IR caching, deferral, and provider switching are the levers; the scheduler is where they live.