Context as Infrastructure: Agents Need More Than Code
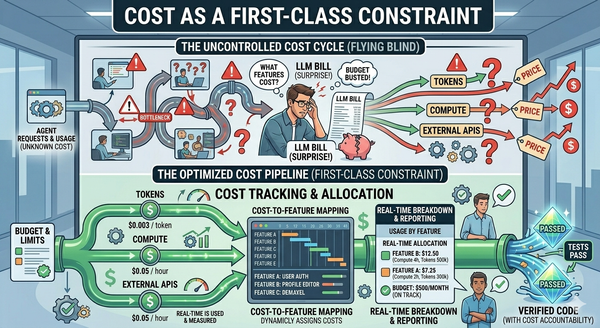
This is Article 10 of Beyond the Coding Assistant, a multi-part series on AI-assisted software engineering at enterprise scale. The full series is available free of any paywall at https://articles.zimetic.com/. Previously: Article 9 — Cost as a First-Class Constraint. Coming next: Article 11 — Review Gates: Where Humans Belong, Where AI Reviewers Belong.
When a human does a security review, they take into account a lot of information in addition to the code. They often have threat models, compliance frameworks and requirements, prior audit findings, team and org specific risk tolerances, etc. In some orgs there are reams of documentation on these in other organizations it is rather sparsely written down but still there is information there somewhere.
When an agent is given this task it is often not given this contextual information and as such it has a much harder job performing a valuable security review for this product. This makes it somewhere between hard and impossible for the agent to do a competent job at this task. The same is the case for performance reviews, and other types of reviews or checks on the code being implemented. Without the context, the agent can't do as well of a job as we would like.
Now some folks have tried to add this kind of information in agent.md files and the like, but that information is often a copy of the actual living documents that contain this information and that leads to drift. This is why just having a prompt or agent definition file that has some of this information does make it a bit better, but doesn't really solve the issue.
The MIT Sloan paper introduced in Article 1 made the structural version of this case: AI's value comes from chaining tasks across workflows, and the cost of every handoff is coordination work — review, validation, adjustment [MIT Sloan: How AI is reshaping workflows and redefining jobs]. Context infrastructure is one of the concrete ways to lower that per-handoff cost. When the next agent in the chain has access to the same documents and decisions the previous agent did, the handoff is much closer to free. When it doesn't, every handoff is a context-rebuild from scratch.
Article 1's iceberg made the same point from another direction. Below the visible coding step are requirements, design docs, architecture reviews, deployment runbooks, monitoring playbooks, security and compliance documents, post-mortems, stakeholder reviews. All of that is context, and all of it is what makes an engineer effective at the visible step. An AI agent with access only to the code is operating with the tip of the iceberg and pretending the rest doesn't matter.
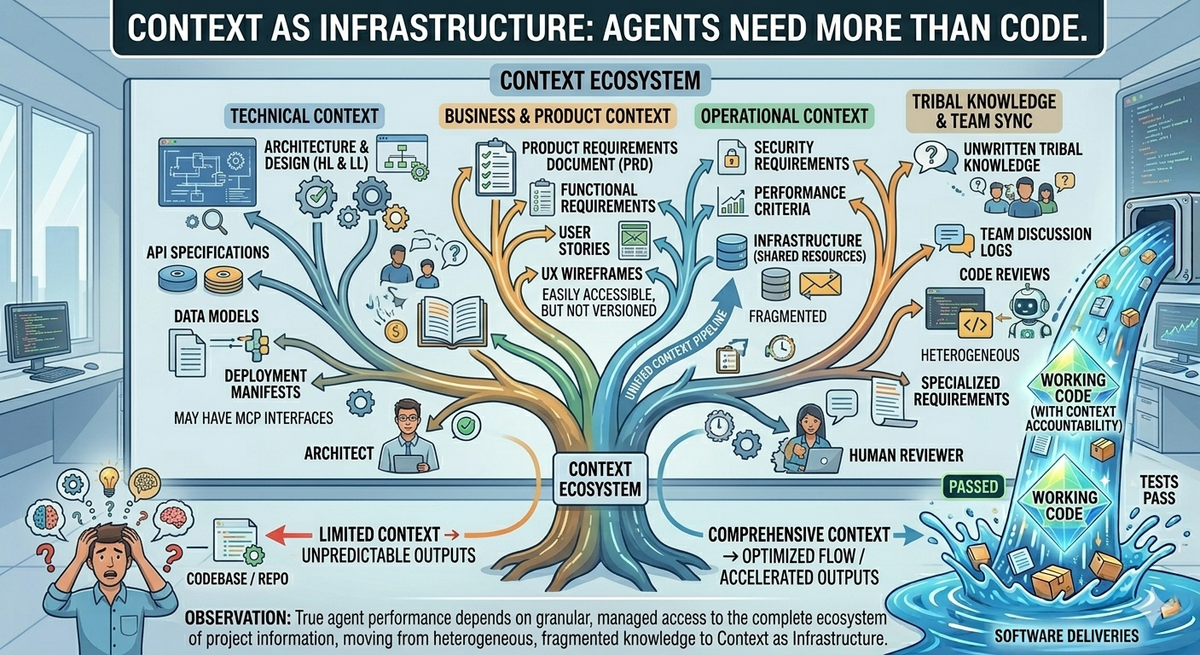
Five types of context
Useful to break this down so the infrastructure requirements get concrete.
- Documents. Security policies, compliance requirements (HIPAA, SOC 2, PCI-DSS as applicable), architecture decisions (ADRs), PRDs, design specs, test plans, coding standards. Things written by humans to be read by humans — now also read by agents.
- Procedures. Runbooks, deployment guides, incident-response procedures. Knowledge about how we do things here. Procedures change less often than documents but matter just as much.
- Knowledge. ADRs, post-mortems, lessons learned. Knowledge about why we do things this way. The institutional memory that prevents the same lesson from being learned five times.
- Shared memory. Cross-agent, cross-session state. Findings from related work. Work-in-progress notes. The substrate that lets two agents collaborate on a single work item across multiple passes.
- Preferences. Team conventions, tooling choices, style guidelines. The texture-level details that make work feel "ours" instead of generic.
Each of these has different storage requirements, different update patterns, different access controls. A context infrastructure that treats them all the same will fail at all of them. And while we would all like to think our project is very organized and clean, in every project there is always the tribal knowledge that isn't written down anywhere, or at least not in any form that we can refer to. The more we have written down, and the more organized it is so that the agents can be pointed to the source of truth for these documents the more skilled and capable the agent can be.
Context scoped to the right boundary
Not all context is organization-wide. Some is organization-wide (the security policy applies everywhere). Some is project-scoped (the conventions for this service may differ from the conventions for another). Some is work-item-scoped (the specific requirements being built right now). Some is session-scoped (the agent's working notes for this run).
The scoping matters because it determines what's relevant, what's authoritative, and who's allowed to read or write it. The agent reviewing a PR for the public API needs the API's design constraints (project-scoped) and the company's API style guide (organization-scoped) and the work item's specific requirements (work-item-scoped) — but not the engineering team's debate from three weeks ago about a different API in a different service (irrelevant to this work).
Treating context scope as a first-class concept — organization, project, work item, session — lets the orchestrator hand each agent exactly the context it needs and nothing more. That's both a quality move (less noise, better answers) and a cost move (smaller context windows on the wire).
The non-developer context story
Engineering context is not just code and ADRs. It includes:
- PRDs from product. The problem being solved, the customer it's being solved for, the success criteria, the explicit non-goals.
- Design specs from UX. The mental model the customer is supposed to have. The accessibility requirements. The patterns the broader product uses.
- Test plans from QA. What scenarios actually need to work. What broke in similar features last time. What edge cases the team has been bitten by.
- Release notes from technical writing. What the customer reads. The framing the company commits to publicly.
- Support tickets from customer operations. What real customers are confused by, broken on, or asking for. The most-grounded source of truth about how the product behaves in the wild.
These are all context that matters to our agents. Unfortunately they are often not easily accessible to the agents. While some of us have mcp servers to make them available, from say jira or confluence or other similar tools in many cases they are not versioned in a way that makes it easy to see what has changed with them. This is why I strongly advise having agents that take these documents and periodically pull that information into the repo as documentation for the system. Then the agents can compare that to the document in confluence and determine if it has been changed and if so, the agent will know we need to determine which parts of our project need to be touched to bring it back in line with the new process.
Shared memory as a coordination substrate
Agents working on related tasks need to share findings and state. The security reviewer's findings should be visible to the implementer who will fix them. The test planner's coverage map should be visible to the code generator. The architect's decisions should be visible to everyone downstream.
Shared memory is the substrate for this kind of inter-agent coordination. Without it, every agent is isolated and the coordination has to happen in humans — which is exactly the bottleneck the rest of the series has been arguing against.
A useful shared-memory model has scope (organization, project, work item, session), provenance (which agent wrote this, when, against what spec), and access control (who can read, who can write). It is a system, not a prompt-engineering trick. RAG and vector stores are a piece of it; they are not the whole story. RAG handles "find relevant documents" reasonably well. It does not, on its own, handle "write durable findings, scope them appropriately, attribute them to the right agent, expose them to the right downstream consumers."
The vector store is a tool. The infrastructure is the system around it.
Access control, provenance, audit
Context is not a free-for-all. Some documents are confidential. Some are authoritative (the published security policy). Some are draft (the architect's working notes). Some are opinions (one engineer's take on a design choice).
Findings need provenance. Which agent wrote this? When? Against which version of the spec? Reviewed by whom? A context system that can't answer those questions will fail any real compliance review, and will produce confusion the first time two agents disagree about whether something is authoritative.
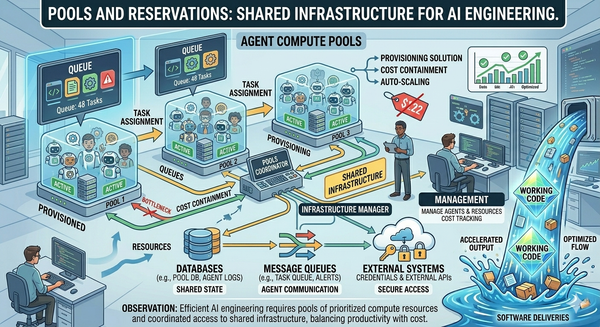
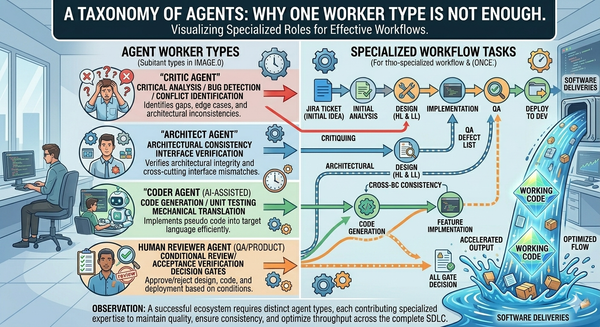
This is also where the infrastructure consumes the work the rest of the series has set up. Article 7's agent specs include context requirements. Article 8's pools and reservation primitives apply to context just as much as to compute. Article 11's review gates use context to define their acceptance criteria. Context infrastructure is connective tissue — it shows up everywhere because it's what makes everywhere coherent.
What this implies for tooling
Several things the infrastructure has to do, none of which today's mainstream AI tooling does cleanly:
- Index everything, not just code. PRDs, designs, runbooks, post-mortems, support tickets, ADRs, the policy library — all of it.
- Scope retrieval to the right boundary. Organization, project, work item, session.
- Track provenance. Every finding tied to the agent that produced it, the version of the inputs it saw, the criteria it was applied against.
- Enforce access control. Confidential is confidential. Authoritative is distinguished from opinion. Audit logs follow.
- Support write-back. Findings, decisions, summaries — durable artifacts the next agent will read.
- Stay current. Stale context is worse than no context, because it's confidently wrong. The infrastructure has to know when sources update and refresh accordingly.
This is the infrastructure work the next generation of AI-assisted engineering depends on. It is unsexy. It is also load-bearing.
Closing
If your AI agents don't have access to the same documents your humans rely on, they will make the same mistakes the humans would have made without those documents — only faster, and at a cost you can't ignore.
A reviewer without the policies is not a reviewer. A test planner without the test history is not a planner. A code generator without the architecture decisions is generating code against a model of the system the rest of the team doesn't share. Context is where AI-assisted engineering graduates from novelty to reliability — and it is where the next several years of competitive advantage are going to come from.
Coming next
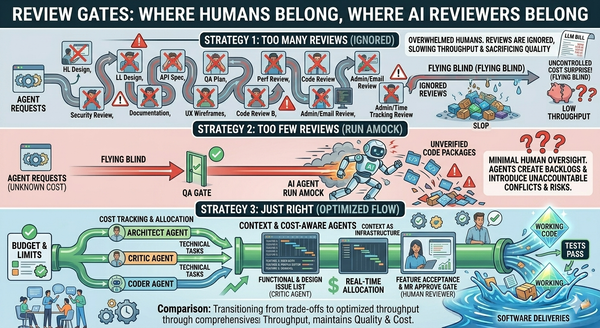
Article 11: Review Gates. The series has now covered infrastructure (pools and reservations), economics (cost), and context. The remaining piece of the principles part is judgment: where humans belong in the loop, where AI reviewers belong, and how the gates that route between them get designed. The whole-team frame from earlier articles makes its loudest reappearance there.