A Taxonomy of Agents: Why One Worker Type Is Not Enough
This is Article 7 of Beyond the Coding Assistant, a multi-part series on AI-assisted software engineering at enterprise scale. The full series is available free of any paywall at https://articles.zimetic.com/. Previously: Article 6 — Structure That Fits the Work: Multi-Pass, Multi-Workflow. Coming next: Article 8 — Pools and Reservations: Shared Infrastructure for AI Engineering.
Ask a security reviewer to also write the feature. You will get mediocre security review.
That's not a slight on security reviewers. It's a structural observation about specialization. Security review and feature implementation involve different context, different tools, different mindsets, different accountability. The two roles exist as separate roles for the same reason most jobs in any complex organization exist as separate roles: specialization is how complex work gets done reliably. Asking one person to do two specialized jobs produces two mediocre results.
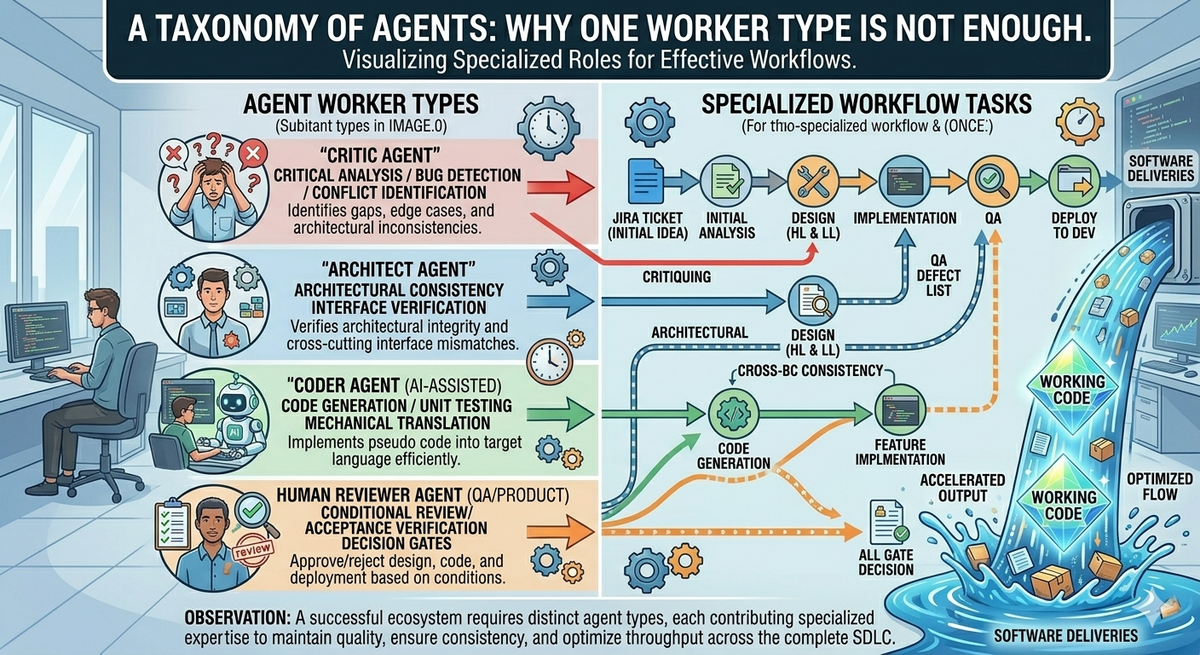
The same holds for AI agents. Asking one agent to play every role in the lifecycle is the AI version of asking the security reviewer to also write the feature. The current default — a single "worker agent" type that the orchestrator hands different prompts to — is a useful starting place that has the same ceiling, for the same reasons. The next step is a taxonomy: agents specialized to roles, with role-appropriate context, role-appropriate model tiers, and role-appropriate accountability.
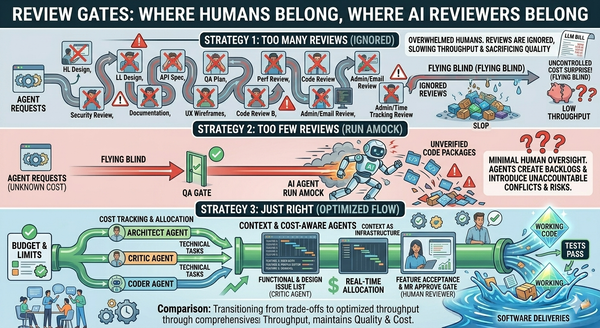
Where the flat "worker agent" model breaks
Most current agentic frameworks assume a single worker type and differentiate by prompt. Send the worker an "implement this" prompt and you get implementation. Send the same worker an "audit this" prompt and you get audit. The framework treats the difference as a string in a system message.
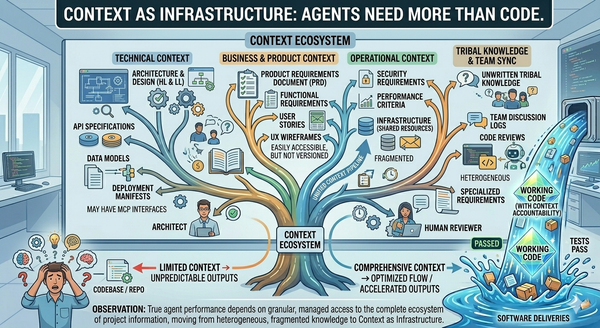
That works for demos. It does not work when the work has distinct phases, distinct accountability, and distinct context requirements. The implementer needs the codebase. The security reviewer needs the threat model and the compliance requirements. The deployer needs the runbook and the rollback plan. The architect needs cross-system constraints.
Trying to load all of that into one agent's context window is a recipe for losing everything when it overflows. They also may need different access and permissions and different components. A QA agent may need to be able to load mock data into a database to test the database access code, where the incident triage agent may need access to production logs. You can't prompt your way out of that.
Article 6 made this structural rather than incidental: different workflows call for different agent sets. A production-bug workflow needs a fast diagnostic agent and a cautious deployer; it does not need a full-spec writer. A new-feature workflow needs an architect and a specifier; it does not need an incident-response triage process. A flat worker pool can't service those workflows well. The agent set has to mirror the workflow set.
A taxonomy — starting with engineering roles
A useful starting taxonomy of agent categories. None of these are canonical; organizations will pick differently and add more.
- Analysts. Interpret tickets, ambient context, recent activity. Produce structured input for downstream agents.
- Architects. Reason about system shape, cross-service constraints, longer-term consequences. Frontier-model work.
- Specifiers. Translate intent into specifications detailed enough that the next pass can be deterministic. Often define interfaces between components or domains so that lower level specification can be done on the internals of those domains. The Spec Kit-style pass agent, generalized.
- Implementers. Generate code, configuration, infrastructure-as-code, schema migrations. The agent everyone already knows.
- Verifiers. Review against criteria. Security review, compliance review, code review, test coverage review — different agents, all in this family. Generators and reviewers are different jobs (more on this below).
- Deployers. Run the rollout. Watch the metrics. Roll back if things look bad. This is orchestration plus judgment, not generation.
- Monitors. Watch production over time, surface drift, surface emerging risk patterns.
- Documenters. Produce and update human-facing artifacts: release notes, README updates, ADRs, customer-facing docs.
- Diagnosticians. The on-call agent. Triages incidents, narrows root cause, hands off to fixers.
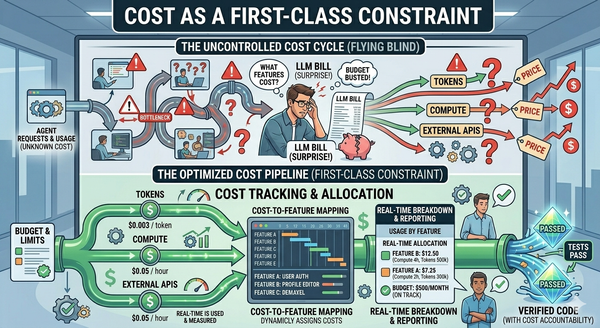
Each of these maps to a different part of the lifecycle, a different context requirement, and (importantly) a different model-tier cost profile. I think the last point is a vital point in defining agents, as well as part of our cost containment going forward is going to be determining the best model to use for the situation. Different task are performed by different agents and each task does not have the same requirements for what model it needs or the same access requirements. Some will need the most expensive models we have access to, but others may be able to get by with much cheaper models.
Engineering is more than developers
The taxonomy can't stop at developer-facing roles. The whole-team frame from Articles 0 and 1 says software is shipped by teams, and the team include product managers, designers, QA engineers, technical writers, program managers, security reviewers, compliance reviewers, and operations staff. Each of these is a candidate for agent support. A taxonomy that only maps developer roles is a taxonomy that perpetuates the bottleneck — because the non-developer work is often where the bottleneck already is.
Concretely:
- Product writes PRDs, triages stakeholder input, owns scope decisions. An assistant agent here drafts initial PRDs from intake notes, aligns wording across stakeholders, flags scope creep before it reaches the engineering pipeline.
- Design produces flows, mockups, design specs. An assistant agent here generates first-pass mockups against constraints, validates a proposed design against an established pattern library, drafts copy variants for A/B testing.
- QA defines test plans and runs exploratory testing. An assistant agent here generates test plans against a spec, identifies gaps in coverage, writes regression scripts for found bugs.
- Technical writing produces documentation that's load-bearing for adoption. An assistant agent here drafts release notes from PR titles, keeps API docs in sync with code, surfaces inconsistencies between docs and behavior.
- Program management tracks dependencies across teams. An assistant agent here surfaces blockers, identifies cross-team coupling, prepares status updates from ticket activity.
These are not "AI replaces the role." They are agents that support the role, the same way the implementer agent supports the engineer. The accountability still lives with the human; the agent reduces toil.
This expansion is where the whole-team frame moves from rhetoric to architecture. If the framework only registers developer-facing agents, it perpetuates the original problem.
Model tiers follow role tiers
Specialization at the agent level enables specialization at the cost level. Different roles want different model capabilities, and matching them is a force multiplier — not a premature optimization.
- Deep-reasoning work (architecture, security review, threat modeling, ambiguous spec work) wants the most capable available model. The cost is justified because the stakes are high.
- Precise, bounded work (spec writing once the design is settled, test plan generation, well-defined refactors) wants a middle tier. Capable enough to be reliable; cheap enough to run often.
- High-volume, bounded work (doc generation, release notes, simple code transforms, classification, summarization) can run on the cheapest model that meets the quality bar. The volume is the point.
In practice what I have found is these "levels" are not as static as this writeup makes them seem. Given a feature, if that feature is relatively small, say impacts a single bounded context in a single repo that is fairly clean and well documented and the feature is easy to reason about, then you can step down on the models here. But if the feature crosses system boundaries, causes changes to contracts between the systems (database schemas, api structures, etc.) and crosses multiple repos or components of the system, well, then we need to level up a level on the models we choose for that feature. So, one of the things I do, is have a clear definition of when to use what model for each task definition in the sdlc.
Agent specs as a definition format
If agents are specialized, how they're specialized becomes a thing teams can write down, version-control, and reason about. The pattern that's emerging — agent definitions as markdown files with YAML frontmatter — is a shape that works. Human-readable. Reviewable in pull requests. Composable across teams. Version-controllable.
A useful spec includes: name, version, category (analyst, architect, etc.), capabilities, context requirements (what scopes the agent reads from), resource access (what it can write to), default model tier, escalation policy. Variations on this idea are showing up across multiple ecosystems; the format is converging because the need is real.
The point isn't a specific syntax. The point is that specialization is something an organization should be able to write down, the same way it writes down code style or branching policy.
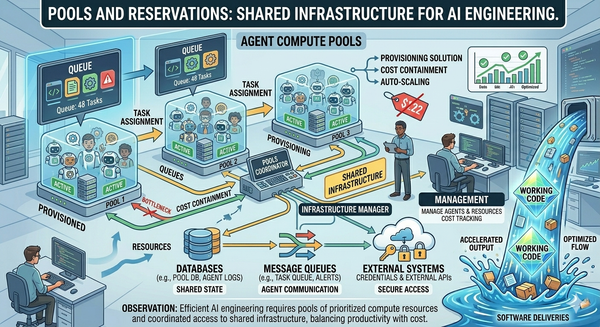
The orchestrator is a different kind of agent
The orchestrator that assigns work, chooses workflows, and manages handoffs is a different kind of agent from the workers that do the work. Worker agents optimize for their specialty. The orchestrator optimizes for coordination: queue management, dependency resolution, escalation, budget enforcement, resource reservation. Combining them is an anti-pattern.
Treating the orchestrator as a worker agent with extra responsibilities is the design error that produces a lot of the chaos in current "multi-agent" systems. The orchestrator's context, its accountability, and its decision-surface are different. It needs to know about all the work, not just one ticket. It needs to know about budgets and capacity, not just acceptance criteria. It needs to coordinate, not generate.
Calling the orchestrator out as a distinct category is one of the highest-value moves in this taxonomy. The next article picks up the consequence: an orchestrator coordinating specialized agents needs an infrastructure model that's different from per-developer sandboxes.
Generators and reviewers are different agents
A code generator and a code reviewer have different jobs. Their context is different (the reviewer needs the policy; the generator needs the spec). Their accountability is different (the reviewer's findings are durable artifacts; the generator's output is one of many candidates). Their model tier may be different (a reviewer for security needs frontier capability; a generator for boilerplate may not). Their bias profile is different — a generator that also reviews its own output is a generator that learns to write code that passes its own self-review, which is a different thing from code that's correct. In the same vein, a generator that writes the code and the unit test always passes it's unit tests. Make them two different agents and they will compete with each other and you will get a better product as an outcome.
Treating "the AI" as one thing that both generates and reviews is the design error Kent Beck has called out in his own AI-assisted work — agents that delete tests to make them pass, agents that ship code that satisfies the agent's own criteria but not the human reviewer's. Separating the two roles is structural protection against that failure mode, not a procedural overhead.
What this buys you
Specialization makes review meaningful (the security reviewer actually has security policies in context). It makes cost traceable (cheap models for cheap work). It makes accountability traceable (the artifact was produced by this agent against this spec, and the chain is auditable). And it opens the door to agents supporting non-developer roles — the largest untapped opportunity in the AI-engineering landscape.
A flat worker pool cannot deliver any of those reliably.
Closing
AI agents will eventually look like engineering organizations. Not because organizations are the right model for everything, but because the division of labor is how complex systems get built reliably, and "everyone is a generalist" is a luxury only small systems can afford.
Your engineering org is a taxonomy of roles, conventions, and handoffs that the people in it understand intuitively. Your agents should be one too — and the framework that runs them should treat their specializations as first-class, not as accidents of prompt wording. That doesn't mean the agents you run and the tasks they do in your sdlc should match identically what your sdlc is or was when humans did all the work. The changing dynamics of the work means we have different requirements for our workflow, so we need to be explicit about determining the best workflow for us within this new system.
Coming next
Article 8: Pools and Reservations. Once agents are specialized, the per-developer sandbox model breaks. Specialized agents need to share infrastructure, queue against organizational capacity, run under organizational priorities, and coordinate around shared resources without stepping on each other. Pools and reservations are the infrastructure consequence of every claim made so far.