Cost as a First-Class Constraint

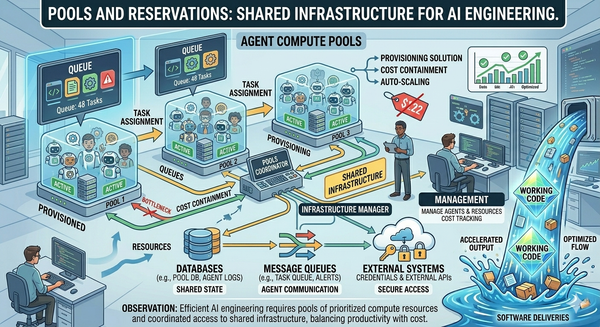
*This is Article 9 of Beyond the Coding Assistant, a multi-part series on AI-assisted software engineering at enterprise scale. The full series is available free of any paywall at https://articles.zimetic.com. Previously: Article 8 — Pools and Reservations: Shared Infrastructure for AI Engineering. Coming next: Article 10 — Context as Infrastructure.*
Imagine writing SQL against a database that never showed you EXPLAIN, never surfaced a slow query, never enforced a statement timeout, and only billed at month-end. You ask the database to do something. It does it, eventually, and bills you for it, eventually. You learn the cost structure by accident — by watching the invoice arrive.
That is what most AI coding agents cost systems looks like today. There is very little visibility into the costs associated with a particular task. Sure, some provide some visibility into who use how many tokens over some period of time, but what tasks does that correlate to? What feature did they work on? How repeatable are these costs? How do they correlate to changes we have made in the sdlc? These and other questions are not something you can answer from the information you can obtain from the model vendors or from any tools available today.
We would not accept this from a database or a cloud vendor. We have spent decades building tooling specifically to avoid this scenario, and we express shock when the bills arrive and the cost overruns are there. When tokens were cheap, and we were just learning how to use these tools this was marginally acceptable. With Axios and others reporting in April 2026 that some companies are now spending more on AI than payroll [Axios] AI spend is beginning to becomes something we are going to have to address and tackle.
From "cost as a billing line" to "cost as a scheduling input"
The frame shift this whole article depends on: cost is not a thing you notice at the end of the month. It is a thing the scheduler reasons about before dispatching work.
A scheduler that can't see cost will optimize for whatever it can see — usually throughput or completion time. That produces decisions like "always use the most capable model for everything" because the most capable model has the highest success rate per attempt, and the scheduler can't see that the success-rate gain isn't worth the 30× cost difference for trivial work.
A cost-aware scheduler optimizes across all three trilemma axes — quality, speed, and cost — at decision time. That is the move.
Model routing by task complexity
The cheapest usable model is the right model for any given task. Not the cheapest model overall — the cheapest one that meets the quality bar for the work in front of it.
Concretely:
- Simple lookups, summarizations, classification, well-bounded transforms: lowest tier.
- Spec writing, test plan generation, well-defined refactors against a settled design: middle tier.
- Architecture, security review, threat modeling, ambiguous spec work, root-cause investigation: top tier.
Article 5 made the link from SDLC granularity to this opportunity: when work is broken into small, well-defined steps, each step becomes a candidate for the right model rather than a default trip to the frontier. Article 7 made the link from agent specialization to the same opportunity: each agent category has a default model tier that fits its job.
The savings compound at organization scale. A team that runs a thousand small documentation tasks a month on a frontier model is paying for capability it doesn't need. The same workload routed correctly costs a fraction. The cost discipline doesn't constrain quality; it puts quality dollars where they actually matter.
Routing also has to be overridable. Sometimes the stakes justify the expensive model even for nominally simple work — a documentation update for a public API that everyone reads probably wants more capability than a routine internal one. The scheduler routes by default; the workflow lets specific gates upgrade the tier when necessary.
Cost management doesn't end at picking the right model
There is a lot more to cost management though than just picking the right model. We also need a framework that can breakdown the actual costs and record them at a granular level. Are we saving money by choosing this model over a more expensive one, or are we iterating three times with this model and then having to bump up to the more expensive model to fix our bugs? What is the cost savings we achieved from using this model, and is it worth the time and other resources we might have lost by using it?
A framework that doesn't report the costs on each task so that it can help to understand this story cost $x, here is the cost for each task and the model it used and the time it took. Those are the core data points that the framework must provide to us so that we can do real cost analysis and justify the models we are using. For some it will be use the better model as the time savings is worth the additional cost, for others it will justify running a local instance of an llm for certain tasks. For others it will be keep using what you are using. But without the data we are flying blind.
Local vs. cloud inference
The 3,000× gap from Article 3 was not a typo. Brad DeLong's piece on data-center economics worked through Marco Arment's 50-Mac-Mini setup and pencilled out per-inference costs that diverge from cloud-API pricing by orders of magnitude for predictable workloads [DeLong, "Is the Day of the Data Center About to End?"]. The Latent Space piece on stacked hardware, quantization, and distillation reaches the same general direction by a different route [Latent Space]. The exact multiplier depends on the workload. The direction is unambiguous.
For predictable, high-volume workloads — doc generation, simple transforms, summarization passes, classification, embedding generation, the kind of work that runs in the same shape thousands of times a day — the cheapest inference is the inference that didn't go to a cloud API at all.
Cloud API calls should be reserved for the work that actually needs frontier capability, the work that's intermittent enough that local hardware sits idle, or the work that has variable shape enough that local optimization isn't worth it.
This is non-trivial to operate. Local hardware comes with its own ops burden — patches, updates, monitoring, hardware refresh. Most organizations won't run their own inference today. The point is that the orchestrator should be able to route to local capacity when it makes sense, and the architecture should make that pluggable. Locking the workflow to a single cloud provider closes off the option.
Since those articles were published, Mac Studios with 512G ram have stopped being sold, and it looks like the 256G ram units will also stop being sold. Mac Minis base model has been discontinued. All reportedly because of the memory shortages going on today. With the massive scale up of data centers, the huge increase in energy demand, constrained manufacturing of chips to perform the inference, and memory chips and other hardware there is likely to be a few years here where we are going to see inference costs get higher and higher. Until the supply and demand stabilize into a predictable growth pattern we should expect that there will be unpredictability in the marketpace for these services and plan accordingly.
Caching intermediate representations
Anywhere the workflow produces a durable, reviewable, validated artifact, the next workflow that needs the same artifact should fetch it rather than regenerate it. Now, how do you do that reliably when someone can make changes at any point in time? Well we do have source code control. Git will tell you what has changed since the last time you generated that DDD model, or created the data schema for that database. This means that if you write your phases correctly, you can actually save alot of usage by only re-generating certain artifacts when necessary and otherwise using them as the source of truth.
This is one reason why I prefer to keep as much in the git repo as possible. It makes for a versioned set of documentation with changes tracked over time. That is much more informational than having six copies in a wiki and hoping the one updated the latest is most accurate.
Budgets at every scope
Budgets exist at the granularities the organization cares about: organization, team, project, work item.
Each scope has limits. Each limit has policies for what happens at thresholds:
- Approaching the limit. Notify owners. Begin slowing down low-priority work in that scope. Surface the trend.
- At the limit. Pause low-priority work. Require explicit approval for new high-cost dispatches in that scope.
- Over the limit. Pause everything. Escalate to the budget owner.
The point is that budgets are control surfaces, not reporting layers. They are not "here's how much you spent" — they are "here's what the system will and won't dispatch." The reporting comes for free; it's the byproduct of the control.
This is exactly the FinOps move that the cloud-cost discipline made in the late 2010s. The lesson is well-trodden: hidden costs are always misallocated, attributable costs are negotiable, and budgets that the system enforces are the only kind that survive contact with end-of-quarter pressure.
A cost-aware scheduling decision
When most people think of budgeting and cost containment, they think of reporting. And reporting is a great thing, being able to identify that our QA runs are costing 3x what it costs to implement the code will tell us where to focus to reduce costs. But the next step is to also look at how do we schedule work in a way to make it fit better within our budgets.
For this, we need to do cost forecasting as well. Once we have a metric for the size of this feature compared to other features, and we know what those other features costs to build, we can forecast costs for a feature. We can then determine if we want the full scope of the feature at that cost, or if we want to descope the feature or work on a different feature all together. This provides an earlier feedback loop data point for our decision making on development efforts. If this feature costs $.50 do we want it? Sure. If it cost's $500 do we want it? Maybe not.
Closing
The scheduler that sees cost can make choices the scheduler that doesn't cannot. Every one of those choices compounds — not just in the invoice, but in the discipline of the team that runs the system. Organizations whose engineering teams build cost awareness in early are going to outperform organizations that learn it under pressure, the same way the FinOps-disciplined cloud teams outperformed the ad-hoc ones a decade ago.
Cost is a scheduling input, not a billing line. Budgets are a control surface, not a reporting layer. The cheapest inference is the inference you didn't have to run. A scheduler that can't see the bill is flying blind.
Coming next
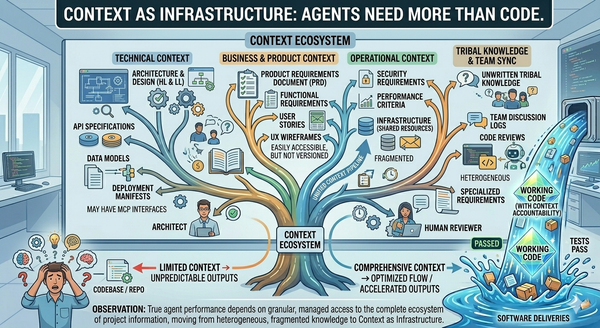
Article 10: Context as Infrastructure. Cost-aware scheduling assumes the agents have what they need to do the work well. That "what they need" is context, and it's a bigger infrastructure problem than most teams realize. Without durable, scoped, version-controlled access to the documents and decisions humans rely on, AI agents cannot do reliable work no matter how well-routed or well-budgeted they are.