SDLC, Not Task: Why the Unit of Work Has to Change
*This is Article 5 of Beyond the Coding Assistant, a multi-part series on AI-assisted software engineering at enterprise scale. The full series is available free of any paywall at https://articles.zimetic.com. Previously: Article 4 — The Quality-Speed-Cost Trilemma of AI Development. Coming next: Article 6 — Structure That Fits the Work: Multi-Pass, Multi-Workflow.*
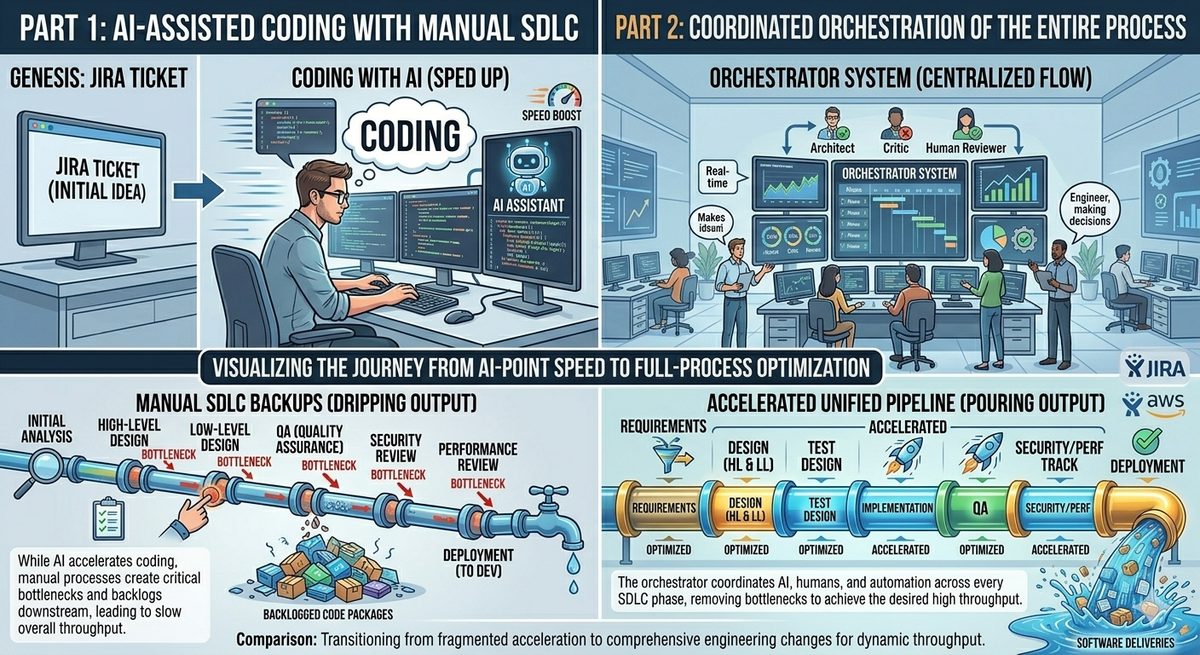
The coding agents do a great job of improving a part of the process. But as we have discussed earlier there are a lot of other steps and when we speed up one but not the others we just move the bottleneck. The engineer feels like they are getting more done, but the team's throughput doesn't improve.
So if we are just moving the bottleneck, how do we actually increase the throughput? Instead of focusing on just writing more code, I believe the next great increase in performance and throughput will be by improving the entire SDLC, or workflow. The process from start to end, from an idea, to a design, and implementation and finishing with a new feature being implemented.
By focusing on the entire lifecycle or process that it takes to develop the software we can improve the speed we deliver features. We can reduce the bottlenecks throughout the process and make adjustments to the process so as to take advantage of the realities of developing software in this new era.
What lifecycle?
Software engineering happens across a lifecycle. Whatever phases an organization uses — ideation, design, specification, implementation, configuration, deployment, refinement, monitoring, debugging, retirement, or some other split — the names don't matter for this argument. The coverage pattern does.
Organizations define their own phases either deliberately (a written SDLC) or by accretion (whatever processes happen to exist). Both are legitimate. Some organizations have six phases, some have twelve. Some have heavy gates between each, some have lighter touches. All of that is fine.
Most teams have agreed upon a lifecycle for their key work, some spoken, some unspoken, some of it written down other parts of it in abstract information, but few actually have it documented in a way that can be used by AI agents so they can move a story from conception to completion.
If we do that, if we define the SDLC, the workflow from beginning to end, then we make it possible for an AI agent to orchestrate the process, keep the story going from one phase or process to the next one. We can also then identify where we have slow downs and where we have friction in our process.
All of this leads to better visibility and awareness of the entire process and makes it easier for teams to identify solutions to that friction. In their paper MIT Sloan argued that AI's biggest impact comes from reshaping entire workflows, not from speeding up any single task in isolation [MIT Sloan: How AI is reshaping workflows and redefining jobs].
Coding agent is dead, long live the coding agent
Let me be clear, I'm not advocating that the coding agent is dead, in fact I'm embracing the coding agent as a central component of this system. I'm just recognizing that the coding step has been vastly speed up and improved. It has moved from being the largest, most time consuming part of the SDLC to now being one of the smallest steps. So, we need to re-imagine our processes and our workflow and make it work for the world we live in today instead of the world we came from two years ago.
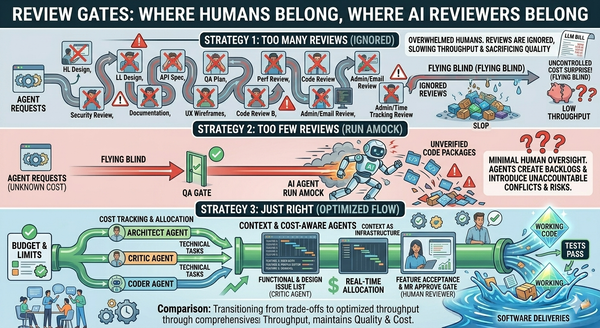
That also doesn't mean we throw away things that have worked in the past. We know that we still need quality gates to verify that something as complex as software systems aren't breaking what was working. We still need consistent deployment processes. We still need solid requirements of what to build. In fact, we will see that we need these things even more as we are more and more able to build and deploy features faster.
At the same time, as we scale up teams of agents all working on features at the same time, we can see that this speed creates more conflicts, more contention for resources, more churn, and this all needs to be taken into account. Most of these problems that occur because we are able to run so much faster are problems we know how to solve. It is just a matter of applying solutions we already know in a way that allow us to run faster and reduces the bottlenecks.
What the framework requires (and what it doesn't)
I have a way in which I suggest we define the SDLC, and it works for my team and others who are using it, but it is not the only approach you can take. The tooling that I am developing works with it, but different tooling will have their own way of defining it. The format of the information isn't as important as the actual definition, and the ability of the AI system to be able to interpret that information. I believe the key take aways are that:
- That an SDLC exists. Written down, deliberate, reviewed. Not "whatever the engineer decided to do today."
- That the SDLC is broken down with enough granularity that an AI agent can reliably execute each step with consistent, trustworthy quality. That doesn't have to mean a fixed number of passes. It means the work is decomposed into units small and well-specified enough that the agents can do them reliably.
The good news is that we already have the building blocks and are good at doing this. The components of a good SDLC are:
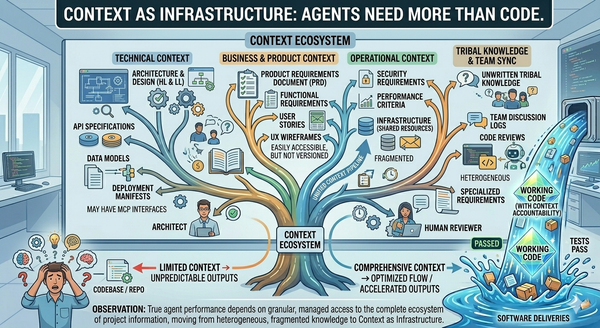
- Inputs. What things need to be there for this task to be able to be performed by whomever is going to perform it. "Before we can write a high level design we must have a PRD or other feature definition."
- Task. The action that is going to be taken on the input to produce the outputs. We also define things about the task, like who performs it, what skills they must have, and resources they need, etc.
- Outputs. What the task should produce.
- Gates. The validation requirements that we need to enforce to verify that the task was completed to our standard and that the outputs of this task will be of sufficient quality to be used as inputs to tasks that need them.
We are very good at breaking big jobs down into individual tasks and assigning them to individuals, which is exactly what we are doing here. One other key learning we have from coding agents is that whenever we assign tasks to AI agents and tools it is best to make those tasks as granular as possible and as well defined as possible.
Research on AI agent task decomposition consistently shows that breaking work into smaller, well-specified subtasks dramatically improves success rates [Amazon Science] [arXiv: TDAG]. At the extreme, GPT-4 hit a 14% success rate on multi-stage benchmark tasks where humans scored above 92% [arXiv: Measuring AI Ability to Complete Long Tasks]. AI tools are great at small, well-defined, bounded work. They struggle on large, ambiguous, multi-step work. The constraint is what shapes the requirement on the SDLC.
Now for what the framework doesn't require, it doesn't require you to use my workflow or even my definition of what these inputs, outputs, tasks and gates are. Different organizations will fill that structure in differently, and they should. Different kinds of work will also want different shapes — a new feature in a complex multi-system codebase wants a different breakdown than a production bug fix. In fact a key component is that you and your team should be able to define what workflows work best for you.
The handoff between team members provides friction
One of the biggest issues with most teams is not the work that has to be done, but the coordination between the different team members on each step of the process. On many teams there are refinement ceremonies and meetings between designers and product managers and then QA disagrees with engineering on the acceptance criteria, and on and on and on.
Because each step is large and each phase is so busy with the story they are trying to focus on to delivery for today, they don't have time to focus on what is coming up. This leads to stories sitting after one team member is done with their part before the next team member is ready to work on that story.
By defining the inputs and outputs and tasks and often by breaking down the steps into smaller components, we reduce these bottlenecks in the process and smooth out the flow. Questions get asked and answered earlier, ambiguity gets settled faster. Teams can hold pair sessions to review the outputs at an earlier stage in the process.
The compounding benefit
This is the payoff that argues hardest for getting the frame right.
Consistent work items, handled through a deliberate SDLC, produce consistent documentation, consistent tests, and consistent higher-quality work products across the whole system. Every new feature built under this model makes the repository and the surrounding systems stronger — better docs, better tests, less undocumented behavior — rather than more fragile.
Imagine if you will, working on a system that has been in production for three years, and finding that it has a current set of documentation you can read that is up to date, accurate, matches the code base and contains all of the latest features in it? No need for tribal knowledge about that feature that was added a year ago by the engineer who is gone now and was a lone wolf. No more finding out that there are three different implementations of the same algorithm which have ever so slightly differences that are not documented and no one knows which one is used in what case. Would that be a project you would like to work on?
Most engineering teams today experience the opposite. Stripe's Developer Coefficient found that roughly 42% of a developer's week goes to dealing with technical debt and bad code [Stripe, 2018]. Each new feature tends to add tech debt faster than the team can pay it down. The system gets more brittle with age, and the AI generation tools available today are perfectly happy to accelerate that decline.
Lifecycle-aware orchestration flips that curve. Over time, the system becomes easier to work on, not harder. If this series has one biggest single argument, this is it: the compounding quality of the codebase over time is the thing most worth optimizing for. A tool that accelerates the coding step without flipping the curve just adds speed to the decline. And one thing I think we can all agree upon is that teams are already fast enough at producing tech debt, what we don't need AI helping us do is creating more tech debt, faster!
Granularity and the cheap-model opportunity
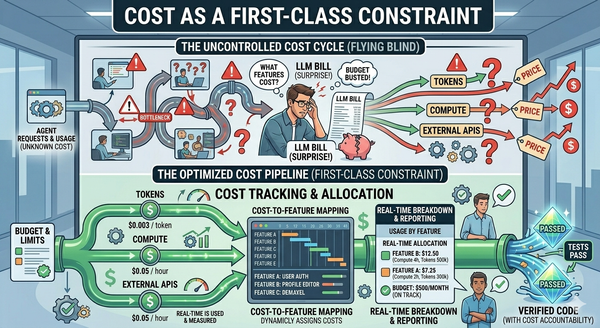
There's a useful secondary effect of getting the granularity right. When work is broken into small, well-defined steps, each step becomes a task that cheaper, faster models can handle reliably. The frontier high-cost models stop being the default for everything; they get reserved for the steps that actually need them — architecture, security reasoning, ambiguous spec work.
Amazon's research has made this point directly: task decomposition combined with smaller LLMs is a key path to making AI more affordable at enterprise scale [Amazon Science]. Given the economics from Article 3, this is not a minor benefit. It's a direct line from SDLC discipline to a sustainable cost curve.
We already have a project management system
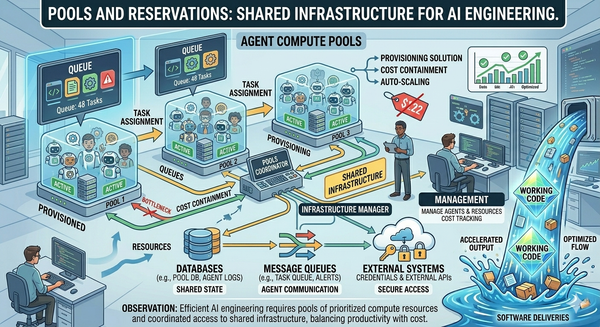
Most teams already have Jira, Linear, or GitHub Issues to manage their projects. And these tools are very valuable. What they do and what I'm describing here are not in conflict with each other. In fact, the two tools work very well together.
What those tools do well is record the progress. They track when each step happened, who commented, which ticket blocks which, what the current status is. That's useful. It's also not enough.
What they don't do is execute. They don't drive the steps, they don't route artifacts between agents, they don't enforce review gates with written criteria, and they don't reason about cost or context. The next generation of AI-assisted engineering tooling needs to cover both sides — recording the work (Jira-class) and executing the work (the thing this series is sketching). They're complementary, not competitive.
Closing
If the lifecycle is the unit and the SDLC defines how it moves, the rest of the series is about the pieces that make it work:
- The shape of each pass within a phase. Article 6 (Structure That Fits the Work) on multi-pass workflows and what task decomposition actually looks like.
- The agents doing the passes. Article 7 on the agent taxonomy.
- The compute they run on. Article 8 on compute pools.
Each one is another step away from the task as the focus and toward the lifecycle as the focus.
Coming next
Article 6: Too Much, Too Little Structure. Why single-pass AI code generation is brittle, why spec-driven development was a helpful start that wasn't enough, and how multi-pass workflows with the right granularity — chosen by the organization, not the framework — produce the kind of results enterprise engineering actually needs.
Sources
- How AI is reshaping workflows and redefining jobs — Kristin Burnham, MIT Sloan Ideas Made to Matter, April 2026
- How task decomposition and smaller LLMs can make AI more affordable — Amazon Science
- TDAG: Dynamic Task Decomposition and Agent Generation — arXiv
- Measuring AI Ability to Complete Long Tasks — arXiv
- The Developer Coefficient — Stripe, 2018