The Quality-Speed-Cost Trilemma of AI Development
This is Article 4 of Beyond the Coding Assistant, a multi-part series on AI-assisted software engineering at enterprise scale. The full series is available free of any paywall at https://articles.zimetic.com. Previously: Article 3 — The End of Cheap AI. Coming next: Article 5 — SDLC, Not Task: Why the Unit of Work Has to Change.
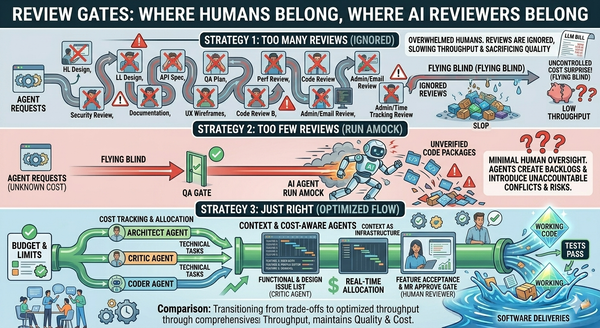
Imagine starting your Monday morning and seeing 200 AI-generated pull requests ready for you to review. The generation step is no longer the bottleneck. The bottleneck is review, it's QA, it's CI. As an overworked engineer you might miss something in one of those reviews that you wouldn't have missed normally. So now the bottleneck is the on-call engineer debugging a weird incident caused by one that slipped through, and it's the CFO looking at the invoice.
"Throughput" without the other two axes is not progress. It's measurable noise. It's increased interruptions which is making you lose track of what is important and what is noise. It is making you feel anxious and leading to you rushing through things that are important. It leads to increased bugs per work completed. And it is a negative flywheel to your teams measurable productivity.
Standing on shoulders
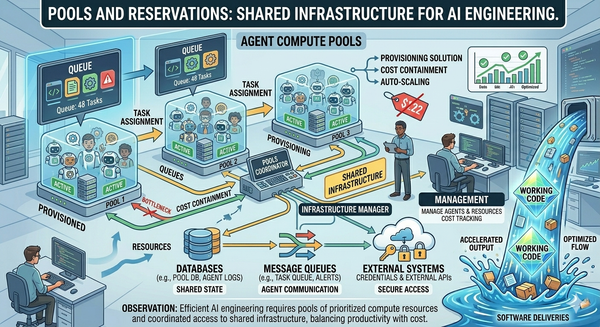
Gas Town — Steve Yegge's multi-agent workspace manager — is the clearest current example of massive-parallel AI coding. The Mayor decomposes a request into smaller tasks. Each project is a Rig, backed by a Git repo. Work is broken into Beads with explicit acceptance criteria. Crews of agents run in parallel, twelve to thirty at a time [Cloud Native Now] [Better Stack].
Gas Town proved several things that nobody had really demonstrated at scale before. You can run a dozen or more coding agents against the same codebase without them tripping over each other. You can integrate directly with GitHub's merge queue and get serial merges on top of parallel generation. You can express work as chained sequences of small tasks ("Beads" in Gas Town's vocabulary) and get convergent outcomes even when individual agents take different paths to get there. That is a genuine step forward. The industry learned a lot from it, and this series builds on those lessons, not against them.
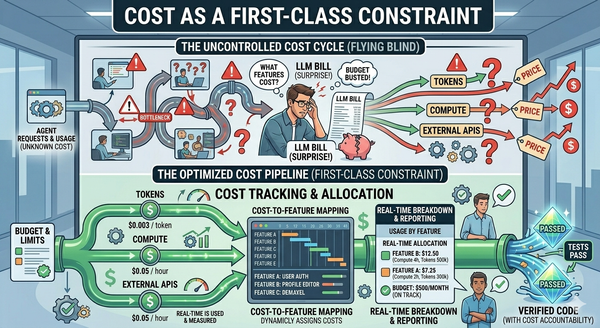
What the Gas Town era assumed, and what is changing, is the background economics. The model was designed for a world of nearly-free tokens, where it was fine to generate five drafts, keep the best, and throw the rest away. One early adopter publicly reported burning $100/hour in API spend during heavy use [Cloud Native Now]. That was a reasonable trade when tokens were a rounding error in enterprise AI budgets. As Article 3 laid out, tokens are no longer a rounding error.
The next chapter has to keep the parallelism thesis and add discipline across the other two axes.
Pick three
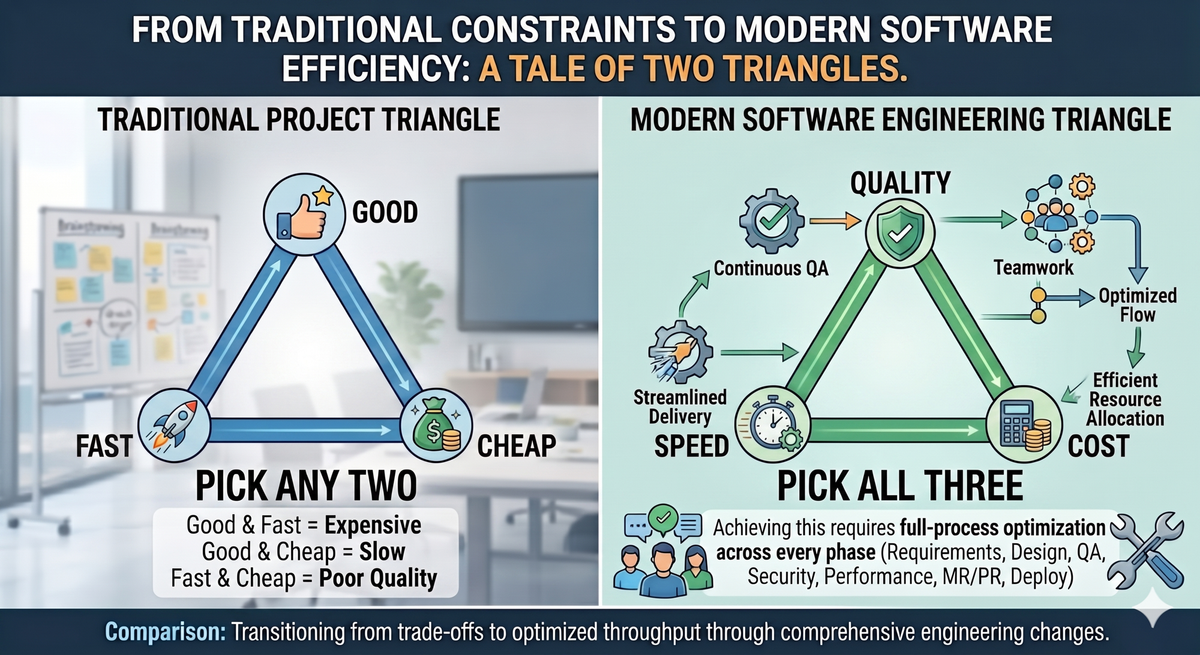
The classic project-management trilemma says: good, fast, cheap — pick two. The twist for AI-assisted engineering is that you don't get to pick two. You have to make explicit trade-offs across all three, because all three are now expensive to externalize.
- Quality can't be treated as "human review's problem" anymore. Review capacity does not scale with generation capacity. If the AI writes 200 PRs and you have three reviewers, the quality floor is set by the reviewers' attention, not by the generator's output.
- Speed can't be the only metric. A team that ships 20 PRs a week with a 30% revert rate isn't shipping 20 PRs a week. It's shipping 14 PRs and creating 6 incidents. Throughput that only measures part way through the development lifecycle is a vanity metric.
- Cost can't be externalized to a provider's margin. That phase of the industry is ending.
Any serious orchestration system in April 2026 and after has to optimize across all three at once.
Why the next chapter looks different
Three things broke simultaneously.
- The pricing broke, we've already discussed that.
- The assumption that human review capacity scales with generation capacity broke — the 2024 DORA data on declining delivery stability as AI adoption rises is the clearest evidence [DORA 2024].
- And the assumption that every team would figure out the right practices on their own broke — the DORA anomaly and the METR finding that experienced developers ran 19% slower with AI tools in a controlled setting [Augment Code summary] both point to the same conclusion: most organizations need more structure around these tools than they currently have.
Quality debt
"Fast and cheap" generates debt downstream. At AI-generation scale, that debt compounds fast. Some examples of what it looks like in practice:
- Generated code that looks right but is subtly wrong. Timezone bugs, off-by-one edge cases, silent bypass of validation checks. The kind of mistake that takes a senior engineer ten minutes to catch and a month to catch after it lands.
- Tests that pass for the wrong reasons. An AI generating a test alongside the implementation tends to produce a test that verifies the implementation it happened to write, not the behavior it was supposed to verify.
- Documentation that drifts from implementation. Especially painful when the AI also happens to read the docs to understand the system — the drift becomes self-reinforcing.
- Small changes that defeat the purpose of the architecture building on top of each other and becoming the norm. AI is great at figuring out the easiest way to close the ticket, it's not always great at figuring out the right way to implement the solution in a way that keeps the system nimble and powerful.
Each of these is a small debt by itself, and on undisciplined teams these add up without ai assistance. However, at ai speeds, and when engineers are not able to pay sufficient attention to the code review process because they are being stretched too thin, these pile up so much faster.
Speed without quality = throughput without progress
A PR that gets reverted wasn't a PR. A feature that ships behind a flag that never rolls out wasn't a feature. Dashboards that measure raw throughput will show those as wins, and the team shipping them will feel productive until the downstream cost arrives as an incident, a customer escalation, or a security finding. However, not only are these not a win, they have a cost associated with them. There was human energy put into them, humans had to ask the agent to do the work, and then had to determine the work wasn't good enough. Sometimes this is after humans have made repeated requests to try to get the agent to do what they wanted.
The math gets worse when AI agents are the reviewers of other AI agents' output. Without deliberate guardrails, it's easy to end up in a closed loop where nothing stops bad work from landing. Kent Beck has described exactly this failure mode when discussing his own AI-assisted work — he talks about AI agents deleting tests to make them "pass" as one of the surprises of the current generation of tooling [Pragmatic Engineer podcast with Kent Beck].
Cost-aware orchestration as the way forward
The only honest response is to treat all three axes as first-class. In practice that means:
- Models routed to tasks by complexity. Cheap models for bounded work; frontier models only when the stakes justify them.
- Track budget and cost on a per item/story basis. The system must provide the cost tracking on a task/story basis and make it easy to report it back to the ticketing system (jira/github/etc).
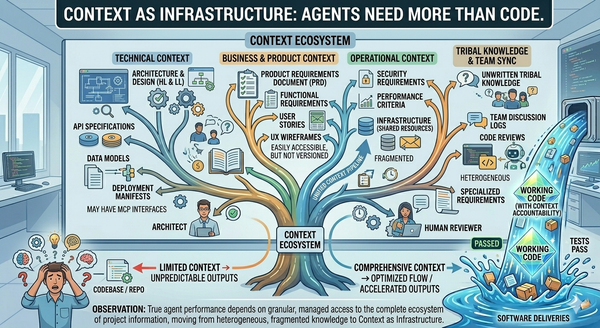
- Intermediate representations that can be validated before code is generated. An IR gives you something to review that isn't a 2,000-line diff, and lets you catch problems before deterministic code generation turns them into production bugs (the next article picks this thread up in depth).
- Switch providers without rewriting workflow. Organizations need to be able to keep costs down by using multiple providers and lower cost models. Some may even choose to run some models internally both for security and for improved performance and cost management.
- Defer low cost work. Some work just may not meet the cost analysis value line.
Each of these gets a dedicated treatment in the rest of this series. The point here is that none of them can be optional if the trilemma is real.
The SDLC is how you navigate the trilemma
So what is the solution? As we will discuss in the next few articles, the way we orchestrate the entire development lifecycle and manage not just the implementation step but the entire SDLC is how we can empower the agents to make the entire pipeline run faster. After all having a bigger pipe in the middle of two small sections of pipe doesn't do anyone any good. This means that we have to be able to structure the entire process — whole-team, beginning to end — so that quality, speed, and cost are reasoned about at the right points.
The way you do that is by breaking the work into smaller, well-defined steps with clear handoffs and clear acceptance criteria between them. GitHub's open-source Spec Kit is a good example of this idea in practice: a toolkit that organizes projects around a .specify directory and a set of slash commands — /speckit.specify to document requirements, /speckit.plan to generate an implementation plan, /speckit.tasks to break the plan into task chunks, /speckit.implement to execute, plus /speckit.clarify and /speckit.analyze to catch inconsistencies before implementation [GitHub Blog] [Spec Kit]. That's essentially a two-pass (sometimes three-pass) approach, and it helped, but often it wasn't enough for most enterprise work.
Real work involves design decisions, constraint reconciliation, multiple verification concerns, integration with other changes, and deployment considerations. Forcing all of that into two or three passes asks too much of either pass. You need the broader SDLC discipline the rest of this series unpacks: multi-pass workflows with the right granularity, different workflows for different kinds of work (feature vs. bug fix vs. security incident vs. migration), specialized agents for each pass, and review gates with written criteria so processes are followed in a repeatable fashion.
Getting the SDLC right is not a separate concern from the trilemma. It is how the trilemma gets navigated.
Implications for leadership
This is a strategic framing problem as much as a technical one.
If your AI strategy is "more PRs," you are optimizing one axis and ignoring the other two. The rollouts that look successful on a quarterly dashboard and disastrous on a 12-month retrospective are the ones that didn't name the trilemma.
The next generation of successful AI-assisted organizations will be the ones that can articulate their trade-offs honestly — in public, to their boards, and in internal planning. Naming what you're optimizing and naming what you're spending to optimize it is not a rhetorical move. It's the beginning of a functioning engineering organization in this new economic context.
Coming next
Part II begins. The next article, SDLC, Not Task, argues that the fundamental unit of work for AI-assisted engineering has to shift from writing the code for a feature to all of the work items in the lifecycle. Every article in Part II is a move on the trilemma; this is where the moves start.
Sources
- Gas Town: What Kubernetes for AI Coding Agents Actually Looks Like — Cloud Native Now
- Building with Gas Town: Multi-Agent AI Development Guide — Better Stack
- DORA | Accelerate State of DevOps Report 2024
- Why AI Coding Tools Make Experienced Developers 19% Slower — Augment Code
- TDD, AI agents and coding with Kent Beck — The Pragmatic Engineer
- Spec-driven development with AI: new open source toolkit — GitHub Blog
- Spec Kit