The End of Cheap AI: What Consumption Pricing Means for Engineering Organizations
This is Article 3 of Beyond the Coding Assistant, a multi-part series on AI-assisted software engineering at enterprise scale. The full series is available free of any paywall at https://articles.zimetic.com. Previously: Article 2 — Why AI Tools Make Some Teams Slower. Coming next: Article 4 — The Quality-Speed-Cost Trilemma of AI Development.
In November 2025, Anthropic began renewing enterprise customers under a new billing structure. The old bundled-token enterprise seats — where a monthly per-seat fee came with a generous pool of tokens and you paid overage rates only if you really pushed the limit — are being retired. In their place: seat fees that cover platform access only, and every token billed at standard API rates on top [IT Brief] [Let's Data Science]. The Register covered it under the headline "Anthropic ejects bundled tokens from enterprise seat deal" in April 2026 [The Register].
This is not the story of an AI company behaving badly. It is the normal technology-maturity curve, arriving on schedule. Every major tech category has gone through it: a cheap-access phase while the vendors build demand, followed by price corrections as demand catches up with capacity. Cloud did this. SaaS did this. It is AI's turn.
The implications for how engineering organizations run are substantial, and the time to adjust is now. Axios reported in April 2026 that some companies are now spending more on AI than on employees' salaries — IT budgets, in their phrase, "getting blown out" [Axios]. Whether that crossover is already happening at a given organization or still a few quarters out, the trend line is unambiguous: as AI usage costs rise to actually cover what providers spend on compute, every company is going to have to choose how it provisions these tools for its workforce. This doesn't have to be an all-or-nothing decision. Smart companies will figure out how to give their engineers enough resources to be meaningfully more productive without giving them unlimited resources to waste. That balance requires monitoring, attribution, and ways to track the cost-benefit of these tools — capabilities that most teams don't have yet.
The subsidy era, briefly
Flat-rate enterprise AI existed for the same reason heavily discounted cloud credits existed in 2014: the providers were buying adoption with margin while capacity was underutilized and the land grab was on. It was a rational strategy for that moment. Nobody involved was under the illusion it would last forever.
Several forces have now made it end faster than anyone expected.
Four forces, acting at once
Consumption pricing. Bundled-token arrangements are being unwound across the industry. Anthropic's transition is the most visible, but it's not unique. Seat fees now cover access; usage is billed per-token at standard rates. That means every token is a cost. There's no more hiding usage inside a fixed fee.
Capacity constraints. Inference infrastructure is not scaling as fast as demand. Price becomes a rationing mechanism when capacity is tight. This isn't about any single vendor's margin strategy — it's about physics and supply chains.
Real-world input costs. The cost stack under AI API pricing is moving the wrong way on multiple fronts:
- Power. Residential electricity prices rose 11.5% in 2025 in the United States, outpacing inflation by more than three-to-one, and projections from the EIA and Goldman Sachs see rates up 40% by 2030 versus 2025 [Goldman Sachs / CNBC] [NPR]. Data centers account for around 40–50% of U.S. electricity demand growth according to Goldman Sachs and the IEA. Near some data centers, wholesale electricity costs up to 267% more than it did five years ago [Bloomberg]. This flows through to API pricing whether anyone likes it or not.
- Memory. High-bandwidth memory (HBM), the memory AI accelerators need, is structurally short. SK Hynix's advanced packaging lines are booked through 2026; Micron's HBM production sold out before 2025 began [Next Platform] [TrendForce]. 1 GB of HBM consumes roughly 4× the wafer capacity of standard DRAM [Tom's Hardware]. DRAM prices were up roughly 90% in Q1 2026 versus Q4 2025 [Enki AI]. AI is bidding up memory for everything.
- Hardware. Even the consumer side has felt it. Apple struggled to keep Mac Minis in stock in early 2026 after "OpenClaw" (a local-inference-oriented agent stack) went viral on them — a small but symbolic data point on how quickly "run it yourself" demand can overwhelm supply [marc0.dev].
The cloud-vs-edge inference gap. Running inference on local or edge hardware can be far cheaper than cloud API calls for predictable workloads. Brad DeLong's widely-read piece on data-center economics uses Marco Arment's 50-Mac-Mini server farm as the canonical example: ~$30,000 of up-front hardware, ~$6,000/year amortized, less than 2 kW total power, versus the OpenAI Whisper API bill the same workload would have generated — which DeLong pencils out at around $1,800 per day per Mac Mini equivalent [DeLong, "Is the Day of the Data Center About to End?"]. A separate analysis at Latent Space works through a ~3,000× efficiency-and-cost improvement from stacked hardware, quantization, and distillation techniques applied to predictable inference workloads [Latent Space]. The exact multiplier depends on the workload, but the direction is unambiguous: not every inference belongs in a frontier-model API call.
Vendor lock-in risk. Deep dependence on one provider means their pricing changes become your pricing changes, with no negotiating leverage. This risk is more salient in April 2026 than it was three years ago.
A worked example
Take a "waves of AI PRs" style setup — a team running massive parallel AI code generation à la Gas Town. Twelve to thirty concurrent agents, each taking on beads of work, each generating and iterating through multiple drafts. Public writeups of early Gas Town adopters have cited API spend on the order of $100/hour in that mode [Cloud Native Now].
Under bundled-token pricing, that $100/hour often disappeared into the enterprise allowance, as long as the team wasn't the highest-usage team on the plan. Under per-token pricing, it doesn't. $100/hour × a normal working week is in the high six figures per year, per team, for just the generation step — not counting validation, review, testing, or deploy. An order-of-magnitude delta between old and new billing isn't a surprise; it's the expected case.
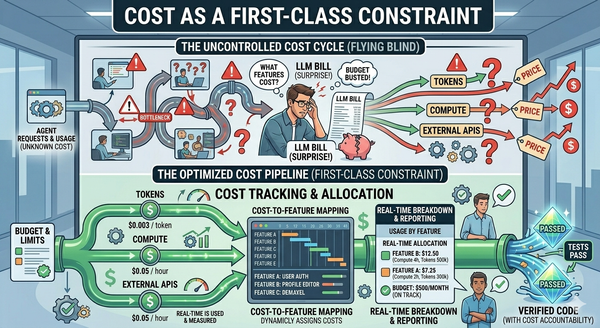
It would not be unexpected for organizations to panic at such a drastic change in their budgets. Many have spent their allocated funds for the entire year in the first quarter. I would expect the costs to continue to rise for the foreseeable future. One of the biggest problems with this is the lack of valuable reporting and cost management tools available. So one of the next things that is going to be needed is ways to manage the costs so an organization can budget confidently.
The cloud-cost analogy
The industry has seen this movie. The late-2010s cloud-cost crisis was created by the same pattern: cheap, abundant new capability → ad-hoc adoption by engineers → six-figure monthly invoices nobody had budgeted for → an entire FinOps discipline emerging to put guardrails on it.
The lessons apply directly to AI spend:
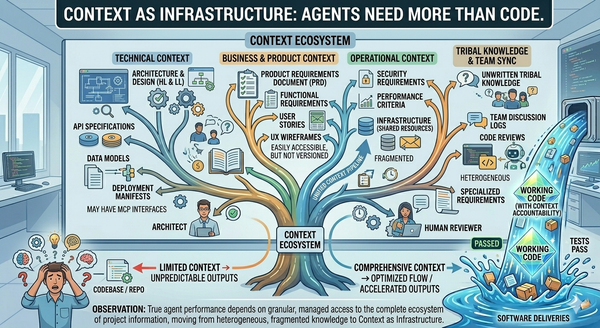
- Attribute cost per workload. If you can't tell what a particular PR, work item, or workflow cost, you can't optimize it. Granular observability is what turns ROI from a feeling into a measurable thing.
- Set budgets at the right granularity. Organization, team, project, and work-item budgets, with policies for what happens as a limit is approached.
- Give teams visibility. Hidden costs are always misallocated. Teams can only make cost-aware decisions if the costs are visible to them in the moment, not three weeks later in a finance report.
- Design for routing between expensive and cheap options. Not every task needs a frontier model; not every workload needs a cloud API call. The orchestration layer should be able to switch models — and over time, decide on its own which model fits the job at hand.
- Don't get locked in. The orchestration layer needs to work across multiple vendors and against self-hosted models in the cloud or on prem. Locked-in customers don't have negotiating leverage when the next pricing change comes around.
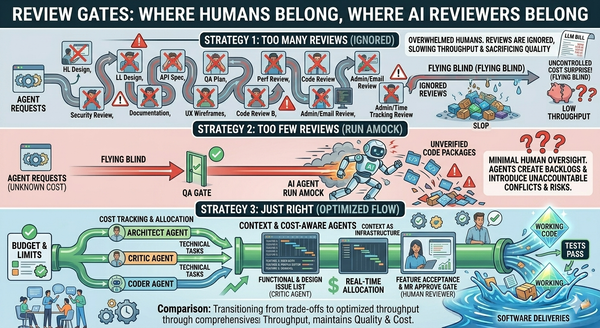
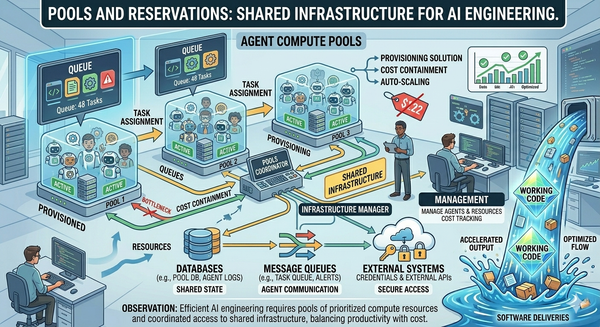
- Pool resources. Per-developer sandboxes don't generalize to team-level cost control. Shared compute pools with queueing and prioritization are how organizations actually contain budgets without strangling individual engineers.
Engineering organizations that treated cloud cost as an afterthought in 2015 spent years paying for that choice. The ones that built cost awareness in early have durable advantages today. The same pattern is setting up around AI spend.
Let engineers play, but do it deliberately
I want to be clear, I'm not advocating for locking down resources so tightly that engineers and team members can't experiment. Experimentation is how we all learn and grow. Treating cost as a first-class constraint does not mean starving engineers of AI access. Every engineering organization needs to give its engineers room to explore what the tools can do, try ideas that don't pan out, and build the kind of taste for AI-assisted workflows that only comes from hands-on time. That's not waste; it's how teams learn to use a new capability well.
The right answer is allocation with awareness. A "learning budget" per engineer. A shared experimentation pool. Visibility into what people are using the tokens on. Retrospectives on what worked and what didn't. The mistake is not giving engineers access. The mistake is giving them unlimited access with no feedback loops, and then being surprised by the bill.
Well-run SDLCs will absorb this; ad-hoc teams will not
Organizations with disciplined SDLCs — defined workflows, staged reviews, budgets at the work-item level, artifact reuse across passes — can adapt to consumption pricing without disruption. They already know what each piece of work is supposed to do and what it's worth spending on. Routing a simple refactor to a cheap model and a security-sensitive change to a frontier model is just another scheduling decision.
Organizations where every engineer uses the tools however they want have a harder landing. Costs spiral because nothing is attributable. Quality wobbles because nothing is routed deliberately. The bill arrives and there's no way to explain it except "everyone's using AI now." That isn't a sustainable answer.
Discipline becomes a competitive advantage. The organizations that build cost awareness and SDLC structure into the orchestration layer now will outperform those that don't — not because of the immediate savings, but because the discipline compounds. Every architectural decision made under cost pressure tends to be more defensible than one made under abundance.
What this favors architecturally
Systems that can do five things will have durable advantages:
- Route between models based on task complexity — cheap models for cheap work, frontier models only when the stakes justify them.
- Track budget and cost on a per item/story basis.
- Cache intermediate representations so yesterday's validated artifact doesn't have to be regenerated today.
- Switch providers without rewriting workflows, including running inference locally for lower cost models if need be.
- Defer low-priority work when budgets tighten.
The pattern underneath all five is the same: tools and processes that give the organization real cost control while preserving each engineer's flexibility to do the job well. Organizations that get that balance right are going to be the winners of this transition. The ones that pick a side — either rationing engineers into uselessness or letting spend run unchecked — are going to lose ground to the ones that don't.
Coming next
In the next article, The Quality-Speed-Cost Trilemma of AI Development, we pull the threads together. Article 2 showed that some teams get slower. Article 3 (this one) showed that the tokens are no longer cheap. Article 4 is about the three-way trade-off that falls out when neither quality nor cost can be externalized anymore — and about how Gas Town and systems like it are a great step forward that this next generation of orchestration builds on.
Sources
- AI can cost more than human workers now — Madison Mills, Axios, April 2026
- Anthropic ejects bundled tokens from enterprise seat deal — The Register
- Anthropic shifts enterprise billing to token-based pricing — IT Brief
- Anthropic Removes Bundled Tokens From Enterprise Seats — Let's Data Science
- Is the Day of the Data Center About to Be Over? — Brad DeLong
- 3000x efficiency improvements in inference — Latent Space
- Electricity prices will keep rising on AI data center demand — CNBC / Goldman Sachs
- AI data centers and electricity prices — Bloomberg
- HBM Supply Curve Gets Steeper, But Still Can't Meet Demand — Next Platform
- AI to consume 20% of global DRAM wafer capacity — TrendForce
- HBM is coming for your PC's RAM — Tom's Hardware
- Mac Mini M4 AI Server + OpenClaw — marc0.dev
- Gas Town: What Kubernetes for AI Coding Agents Actually Looks Like — Cloud Native Now